Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på Twitter
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på Twitter

In this blog series we’ll build Microservices using the Go programming language and piece by piece add the necessary integrations to make them run nicely on Docker in swarm mode within a Spring Cloud / Netflix OSS landscape.
If you’re unsure what a microservice is, I suggest reading Martin Fowler’s article about them. For more about the operations model for microservices, this blog post from my colleague Magnus explains the key concepts really well.
This blog series won’t be a beginner’s guide to coding in Go, though we will nevertheless write some code as we progress through the series and I’ll explain some key Go concepts along the way. We’ll be looking at a lot of code especially during the first parts where we’ll cover basic functionality, unit testing and other core topics.
Part one will be an introduction to key concepts and the rationale for exploring the possibilities with Go-based microservices.
Note: When referring to “Docker Swarm” in this blog series, I am referring to running Docker 1.12 or later in swarm mode. “Docker Swarm” as a standalone concept was discontinued with the release of Docker 1.12.
The image below provides an overall view of the system landscape we’ll be building throughout this blog series. However, we’ll start by writing our first Go microservice from scratch and then as we progress along the parts of the blog series, we’ll get closer and closer to what the image below represents.
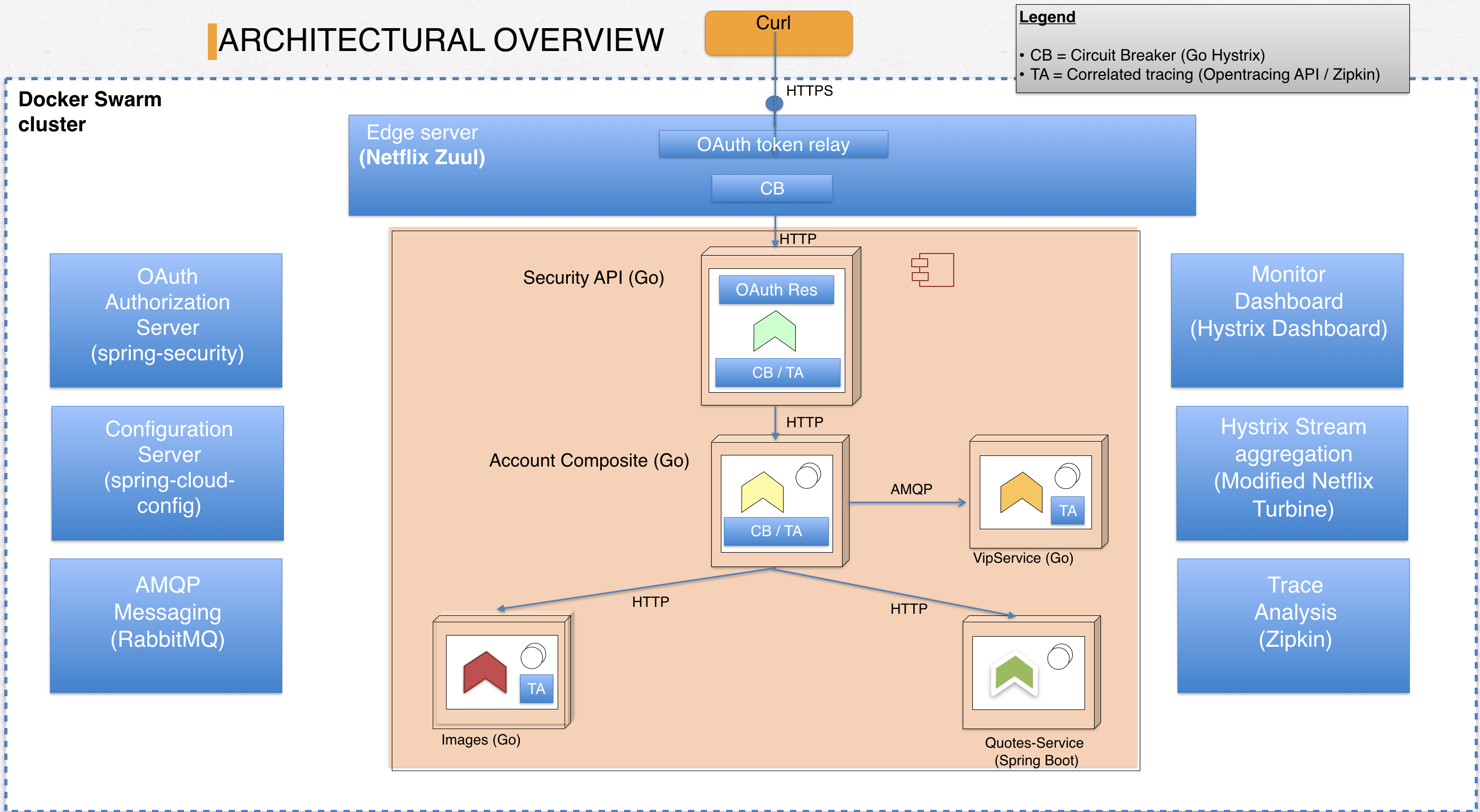 The legend is basically:
The legend is basically:
It’s more or less the same landscape used in Magnus Larssons microservices blog series, with the main difference being that the actual microservices are implemented in Go instead of Java. The quotes-service is the exception as it provides us with a JVM-based microservice we can use for comparison as well as a testbed for seamless integration with our Go-based services.
Why would we want to write microservices in Go, one might ask? Besides being a quite fun and productive language to work with, the main rationale for building microservices in Go is the tiny memory footprint Go programs comes with. Let’s take a look at the screenshot below where we are running several Go microservices as well as a Microservice based on Spring Boot and Spring Cloud infrastructure on Docker Swarm:

The quotes-service is the Sprint Boot one while the compservice and accountservice ones are Go-based. Both are basically HTTP servers with a lot of libraries deployed to handle integration with the Spring Cloud infrastructure.
Does this really matter in 2017? Arn’t we deploying on servers these days with many gigabytes of RAM that easily fits an impressive number of let’s say Java-based applications in memory? That’s true - but a large enterprise isn’t running tens of services - they could very well be running hundreds or even thousands of containerized (micro)services on a cloud provider. When running a huge amount of containers, being resource-efficient can save your company a lot of money over time.
Let’s take a look at Amazon EC2 pricing for general purpose on-demand instances (per 2017-02-15):
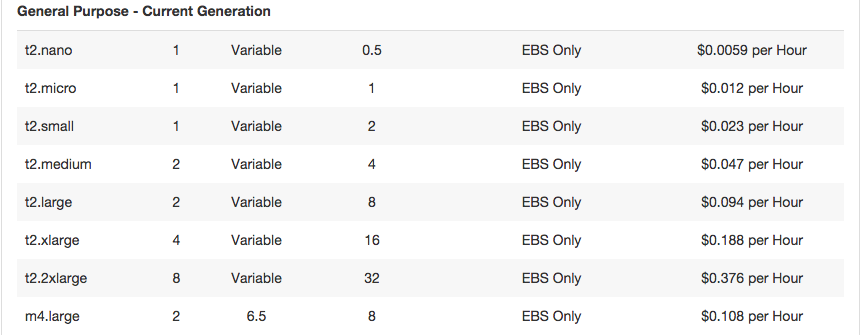
Comparing the various t2 instances, we see that for a given CPU core count, doubling the amount of RAM (for example: 4 to 8 GB from t2.medium to t2.large) also doubles the hourly rate. If you’re not CPU-constrained, being able to fit twice the amount of microservices into a given instance could theoretically halve your cloud provider bill. As we’ll see in later blog posts, even when under load our Go services use a lot less RAM than an idling Spring Boot-based one.
This blog series is not just about how to build a microservice using Go - it’s just as much about having it behave nicely within a Spring Cloud environment and conform to the qualities a production-ready microservice landscape will require of it.
Consider (in no particular order):
All of these are things I think you must take into account when deciding to go for a microservice architecture regardless if you’re going to code it in Go, Java, js, python, C# or whatever’s your liking. In this blog series I’ll try to cover all these topics from the Go perspective.
Another perspective are things within your actual microservice implementation. Regardless of where you’re coming from, you probably have worked with libraries that provides things such as:
I won’t touch on all of these topics. If I would, I could just as well write a book instead of a blog series. I’ll cover at least a few of them.
A basic premise of the system landscape of this blog series is that Docker Swarm will be our runtime environment which means all services - be it the supporting ones (config server, edge etc.) or our actual microservice implementations will be deployed as Docker Swarm services. When we’re at the end of the blog series, the following Docker command:
docker service ls
Will show us a list of all services deployed in the sample landscape, each having one replica.
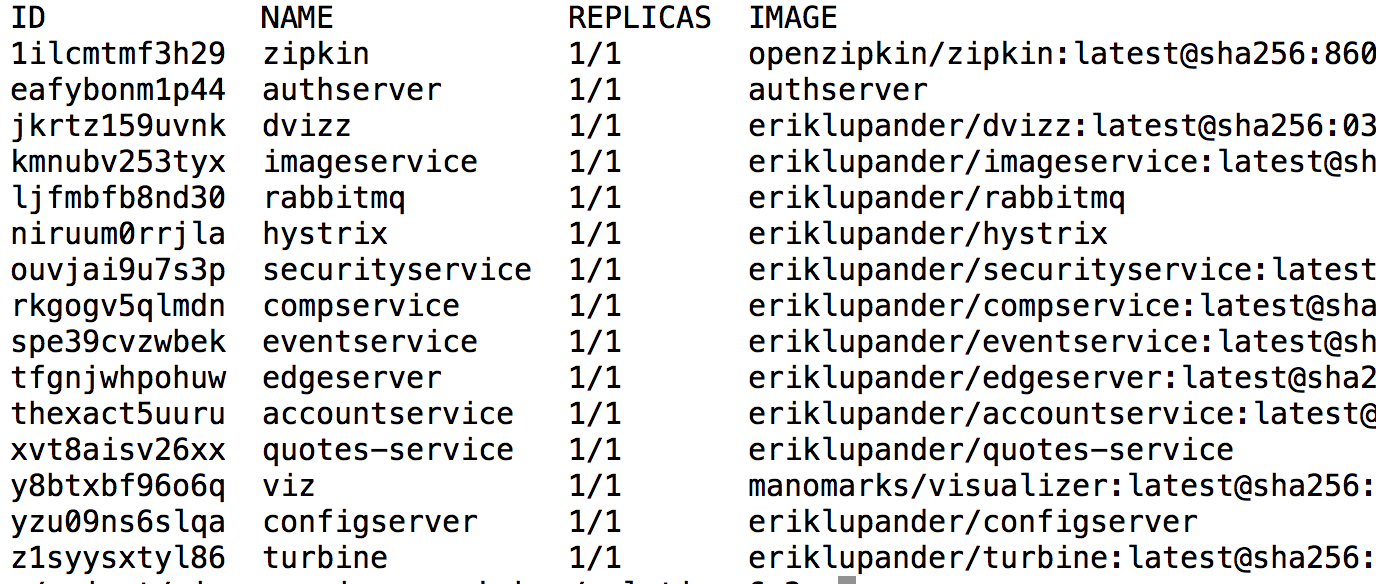
Again - please note that the services listed above includes a lot more services than we’ll have when we’ll setup up our Swarm cluster in Part 5 of the blog series.
Ok - so Go microservices has a small memory footprint - but will they perform? Benchmarking programming languages against each other in a meaningful way can be quite difficult. That said, if one looks at a site such as Benchmarkgame where people can submit implementations of explicit algorithms for a variety of languages and have them benchmarked against each other, Go is typically slightly faster than Java 8 with a few notable exceptions. Go in it’s turn, is typically almost on par with C++ or - in the case of a few benchmarks - a lot slower. That said - Go typically performs just fine for typical “microservice” workloads - serving HTTP/RPC, serializing/deserializing data structures, handling network IO etc.
Another rather important attribute of Go is that it is a garbage collected language. After the major rewrite of the Garbage Collector for Go 1.5 GC pauses should typically be a few milliseconds at most. If you’re coming from the world of JVMs (as I do myself), the Go garbage collector is perhaps not as mature but it does seem to be very reliable after changes introduced somewhere after Go 1.2 or so. It’s also is a miracle of non-configurability - there is exactly one knob (GOGC) you can tweak regarding GC behaviour in Go which controls the total size of the heap relative to the size of reachable objects.
However - keeping track of performance impact as we’ll build our first microservice and then add things like circuit breakers, tracing, logging etc. to it can be very interesting so we’ll use a Gatling test in upcoming blog posts to see how performance develops as we add more and more functionality to the microservices.
Another nice characteristic of your typical Go application is that it starts really fast. A simple HTTP server with a bit of routing, JSON serialization etc. typically starts in a few hundred milliseconds at the most. When we start running our Go microservices within Docker containers, we’ll see them healthy and ready to serve in a few seconds at most, while our reference Spring Boot-based microservice typically needs at least 10 seconds until ready. Perhaps not the singularly most important characteristic, although it can certainly be beneficial when your environment needs to handle unexpected surges in traffic volumes by quickly scaling up.
Another big upside with Go-based microservices in Docker containers is that we get a statically linked binary with all dependencies in a single executable binary. While the file isn’t very compact (typically 10-20 mb for a real microservice), the big upside is that we get really simple Dockerfiles and that we can use very bare base Docker images. I’m using a base image called iron/base that weighs in at just ~6 mb.
FROM iron/base
EXPOSE 6868
ADD eventservice-linux-amd64 /
ENTRYPOINT ["./eventservice-linux-amd64", "-profile=test"]
In other words - no JVM or other runtime component is required except for the standard C library (libc) which is included in the base image.
We’ll go into more detail about how to build our binaries and that -profile=test thing in later blog posts.
In this blog post, we introduced some of the key reasons for building microservices using Go such as small memory footprint, good performance and the convenience of statically linked binaries.
In the next part, we’ll build our first Go-based microservice.