Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

In earlier blog posts we have looked at some of the popular schema frameworks that are commonly (although not exclusively) associated with Kafka - Avro, Protobuf and JSON Schema.
This blog post will consider some aspects of choosing a schema framework (part one), and look at the Schema Registry and the role it plays in organising, communicating and enforcing your schemas (part two).
This blog post is supported by a working example with source code that can be found in this GitHub repository.
The application collects weather reports from a number of weather stations which are published to Kafka according to Avro, Protobuf and JSON-Schema schemas. The application also consumes the same messages, an unlikely use case in reality but useful to illustrate deserialization.
The example is built using Quarkus and the focus of this blog is heavily skewed towards Java and the Java tooling. Although there is support for schemas and schema registry in other languages (libserdes for example) this is considered out of scope.
When data is structured there is a need to be able to express that structure, for example using COBOL copybook, SOAP or XSD, or OpenAPI specifications. A schema is one way to express a data structure, providing context about the data itself and providing constraints for that data.
In our weather report example the schemas express a structure that contains information regarding the location of the weather station and observations of the weather. The schema provides context where, for example, a precipitationRate observation is described as Volume of rain in the last hour (mm). Constraints can be provided, for example a visibility reading is expressed as an enum to restrict what could otherwise be quite a subjective reading.
Using JSON Schema to produce a Weather Schema results in a human readable schema document. This is very similar to how most public APIs are expressed (using OpenAPI for example) where one aspect is accessibility for those who will consume the API.
A quick look at the schema shows that the schema contains an identifier:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://se.martin/weather-schema.json",
"title": "Weather",
"description": "A schema for weather readings",
}
The data structure is expressed in a verbose manner and it is easy to add a description and examples to aid the consumer.
"location": {
"description": "location of reading",
"type": "object",
"properties": {
"name": {
"description": "Common name for station",
"type": "string",
"examples": ["Stockholm Waether Station 1"]
},
"required": [
"stationId", "latitude", "longitude"
]
}
If your need is to express your data structure to a wide audience then JSON Schema may well be your best fit. Most developers and even non-technicians can follow a JSON schema. For example if you are defining schemas for an event that is common for multiple systems or units in a large organisation it may be preferable to express this using a JSON schema.
JSON Schema is not associated with and does not provide tooling for serialization or deserialization. In this example Quarkus is using the well known and loved Jackson library to map between Java object and JSON. In part 2 we will look in more depth at the role of the schema in serialization and deserialization, but note here that the Jackson library itself does not provide any validation of the JSON against the JSON schema.
In addition the Quarkus framework is using the SmallRye Reactive Messaging framework which in turn is using Jackson and a Kafka Client to serialize data. This complicates matters should you wish to write simple unit tests to ensure schema validation is being performed (more in part 2).
One aspect of serializing to JSON is that the serialized data is also human readable - if a user has access to a topic through tools such as KafkaCat or Confluent Control Center the data will be easy to access (see the screenshot below). If you are storing confidential data you may need to consider further steps to ensure the data is protected.
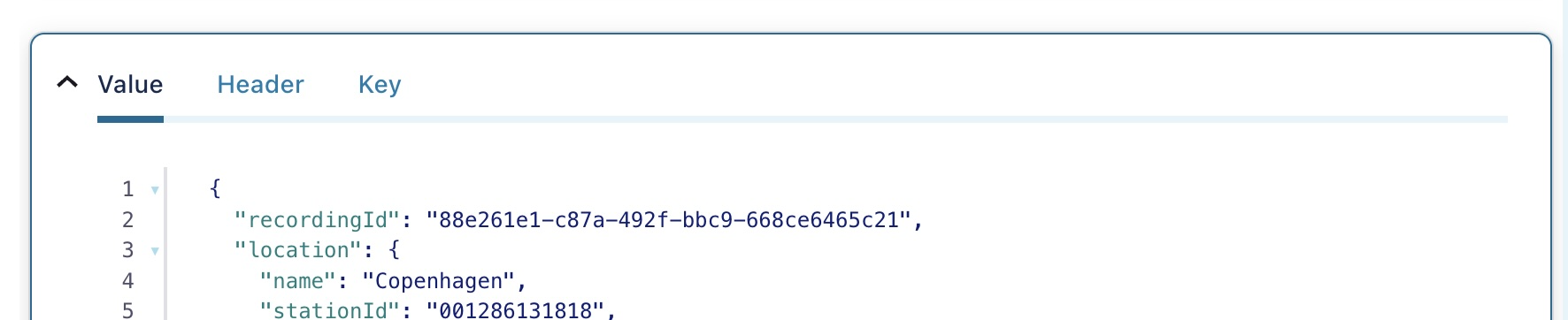
Using Apache Avro to produce a Weather Reading schema produces another human readable object. The schema itself contains an identifier:
{
"namespace": "se.martin.weather.avro",
"name": "WeatherReading",
}
Fields are expressed in a similar way, providing doc fields for documentation and providing constraints as in the example below where the enum constrains the values of a field and type can be used to distinguish between optional and manadatory fields:
{
"name": "visibility",
"type": [
"null",
{
"namespace": "se.martin.weather.avro",
"name": "Visibility",
"type": "enum",
"symbols": [
"good",
"average",
"poor",
"total_utter_darkness"
],
"doc": "Perceived visibility measurement"
}
]
}
Quarkus has been configured to generate Java classes from the schema (once the project is built the generated java classes can be found in the /build/classes/java/quarkus-generated-sources/avsc folder).
One useful feature of these generated classes is that they perform validation against the Avro schema . In this example the
WeatherReadingMapper
class encapsulates the mapping from domain object to the Avro WeatherReading class, and this class is unit testable (see
WeatherReadingMapperTest
). This allows us to find potential errors at build time, which is preferable to runtime, especially in production when running at scale.
Should the mapping fail there will be hints as to why (see below):
Field stationId type:STRING pos:1 does not accept null values
org.apache.avro.AvroRuntimeException: Field stationId type:STRING pos:1 does not accept null values
at org.apache.avro.data.RecordBuilderBase.validate(RecordBuilderBase.java:91)
In this example Avro is serializing to a binary format (though JSON could be used), which as illustrated below, makes it more difficult, but not impossible, to read the data from the topic. This offers some protection against unwanted access but also will make debugging more difficult.

Expressing our weather readings using Protobuf results in a more technical format. The schema contains messages which are supported by a domain name (or package). Fields are assigned a field number which should not be changed (more on this in part 2). Some constraints can be applied, such as optional fields and enumerations. Documentation is in the form of comments in the schema.
// A schema for weather reports
message WeatherReport {
string recordingId = 1; // A unique id for the recording
Location location = 2; // location of reading
string observationTimeUtc = 3; // Time of recording (UTC)
optional Observations observations = 4; // Measurements taken in the reading
}
Quarkus has been used to generate Java classes from the protobuf schema (after build these can be found in the /build/classes/java/quarkus-generated-sources/grpc folder). As for the Avro case it is possible to encapsulate the mapping to and from a Protobuf generated object and to write unit tests (see the
WeatherReportMapper
and
WeatherReportMapperTest
classes).
There is some validation against the schema, however this can be in the form of the dreaded NPE:
java.lang.NullPointerException
at se.martin.weather.proto.Location$Builder.setStationId(Location.java:788)
at se.martin.weather.proto.WeatherReportMapper.from(WeatherReportMapper.java:26)
at se.martin.weather.proto.WeatherReportMapper.from(WeatherReportMapper.java:19)
at se.martin.weather.proto.WeatherReportMapperTest.testMapping(WeatherReportMapperTest.java:22)
Protobuf uses a binary format for serialization, similar to Avro, which again makes it somewhat difficult, but not impossible, to read the data straight from the topic.

Usability and tooling are important aspects but other aspects should be considered.
Sizing your topic is important and it can be a good idea to perform some form of calculation on how much data will be retained. For this you will need to know the retention period of the topic, the expected volume of messages in the retention period and the size of the messages.
To illustrate this I have taken a snapshot of each topic size after 10 minutes of execution, in which 4800 messages are produced. The same message data is sent to each topic so differences in topic size can be attributed to the method of serialization. The snapshot shows:
Although the size of the individual message is trivial it does illustrate that the choice of schema will affect the size of your topics when running at scale.
This blog post has taken a surface look at three schema frameworks that are frequently associated with Kafka. In part two we will take a deeper look at how schemas can be enforced and evolved using a schema registry.