Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

This is not yet another introduction to microservices, for a good introduction please read Fowler - Microservices. Instead this blog post takes off assuming that we already have started to use microservices to decompose monolithic applications for improved deployability and scalability.
When the number of deployed microservices increase in a system landscape new challenges will arise not apparent when only a few monolithic applications are deployed. This blog post will focus on these new challenges and define an operations model for a system landscape deployed with a large number of microservices.
The blog post is divided in the following sections:
To start with, what is required to roll out large numbers of microservices in the system landscape?
According to Fowler’s blog post, this is what we want to achieve:
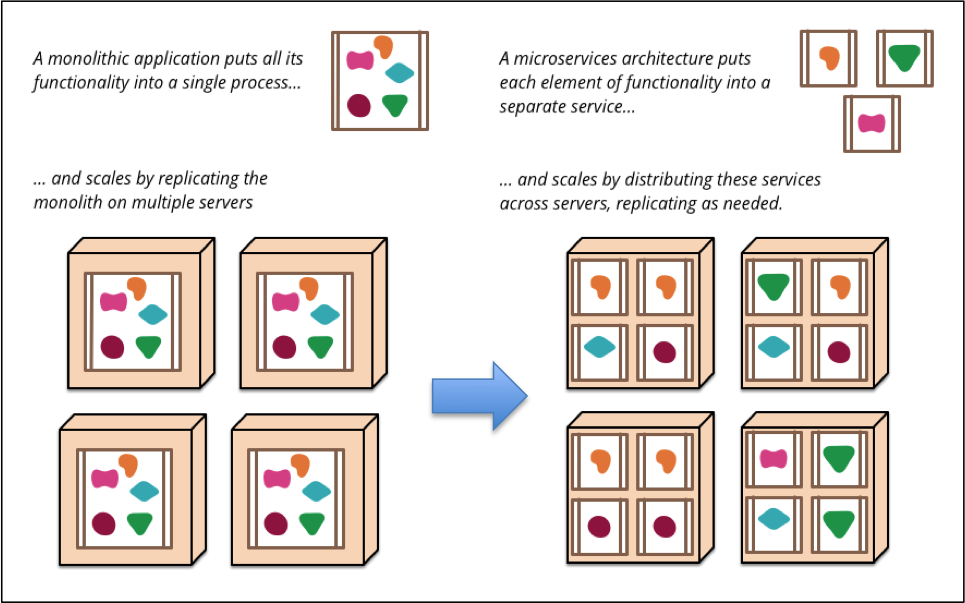 (Source: http://martinfowler.com/articles/microservices.html)
(Source: http://martinfowler.com/articles/microservices.html)
However, before we can start to roll out large number of microservices in our system landscape replacing our monolithic applications there are some prerequisites that needs to be fulfilled (or at least to some extent). We need:
Let’s briefly look a each prerequisite.
First we need an architectural idea of how to partition all our microservices. We can for example partition them vertically in some layers like:
…and horizontally we can apply some domain driven partitioning. This can result in a target architecture like:
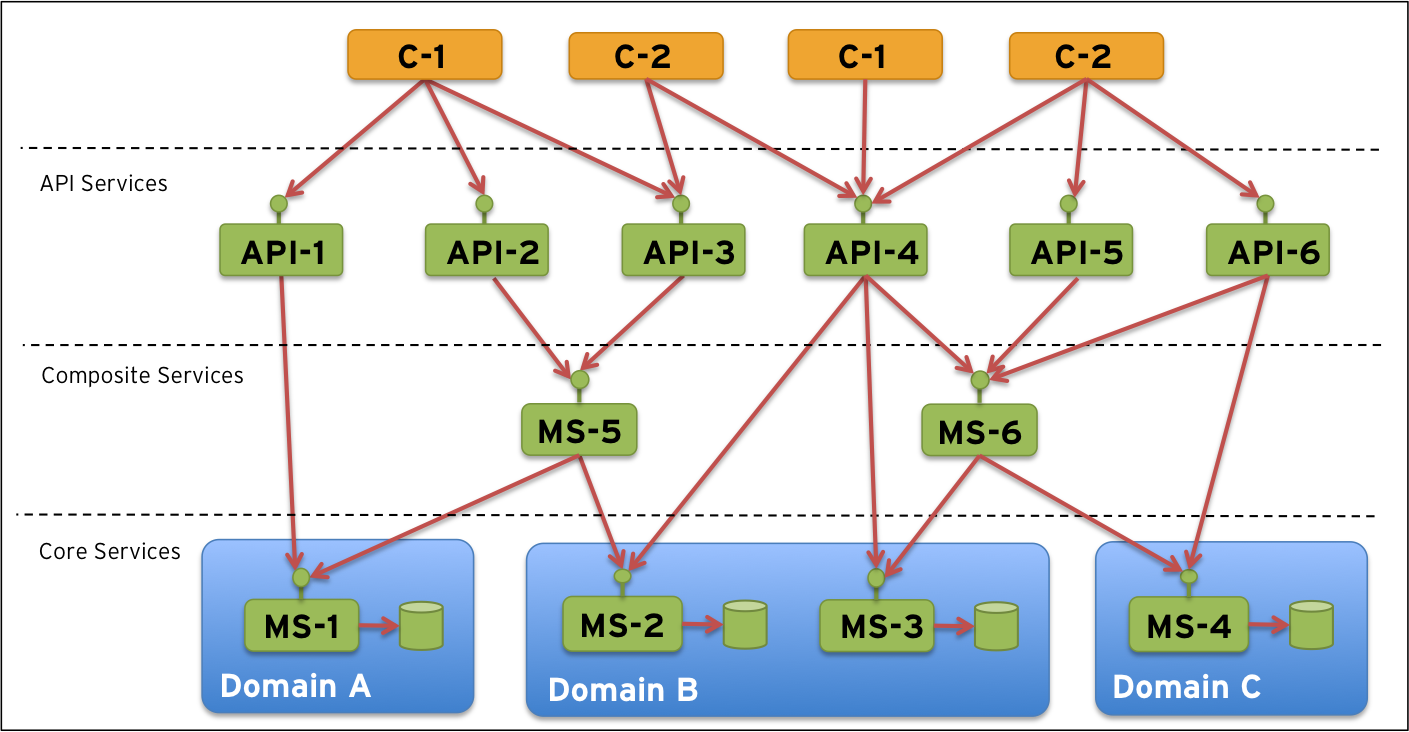
Note: This is only a sample target architecture, your architecture can be completely different. The key thing here is that you need to have an target architecture established before you start to scale up deploying microservices. Otherwise you might end up in a system landscape that just looks like a big bowl of spaghetti with even worse characteristics than the existing monolithic applications.
We also assume that we have some kind of continuous delivery tool chain in place so that we can roll out our microservices in an efficient repeatable and quality driven way, e. g.:
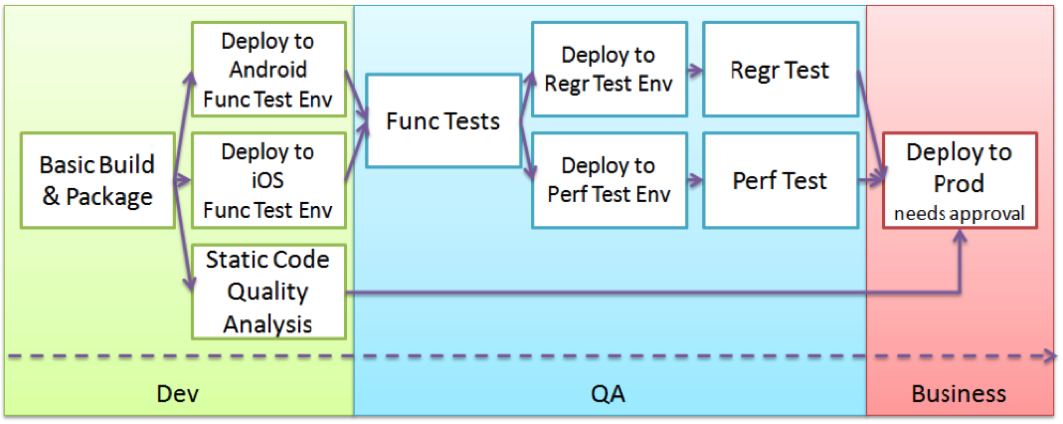 (Source: http://www.infoq.com/minibooks/emag-devops-toolchain)
(Source: http://www.infoq.com/minibooks/emag-devops-toolchain)
Finally, we assume that we have adopted our organization to avoid issues with Conway’s law. Conway’s law state that:
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
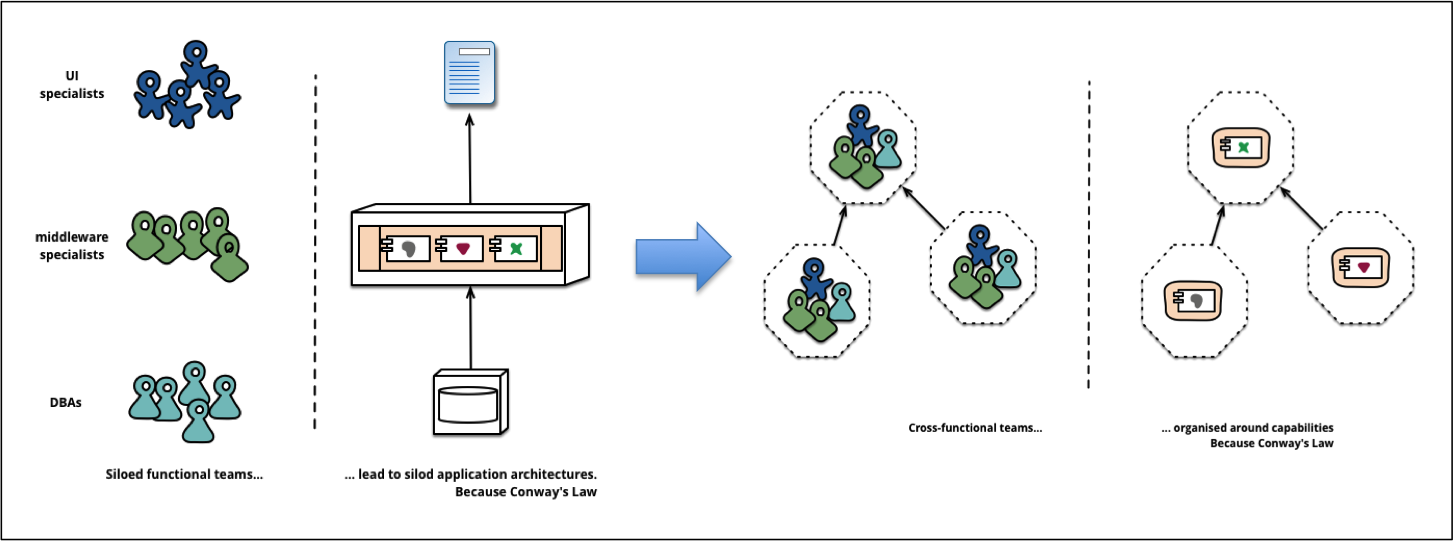 (Source: http://martinfowler.com/articles/microservices.html)
(Source: http://martinfowler.com/articles/microservices.html)
So, now over to the part that this blog post will focus on:
What will happen in a system landscape when we start to split up a few monolithic applications and replace them with a large number of microservices?
Larger number of deployed units Many small microservices instead of a few big monolithic applications will, of course, result in a significantly increased number of deployed units to manage and keep track of.
The microservices will both expose and consume services This will resulting in a system landscape where the most of the microservices are interconnected with each other
Some microservices will expose an external API These microservices will be responsible for shielding the other microservices from external access
The system landscape will be more dynamic New microservices are deployed, old ones are replaced or removed, new instances of existing microservices are started up to meet increased load. This means that services will come and go at a much higher frequency then before.
MTBF will decrease, e.g. failures will happen more frequently in the system landscape Software components fails from time to time. With a large number of small deploy units the probability that some parts (even though small) in the system landscape is failing will increase compared to a system landscape with only a few big monolithic applications.
This will result in a number of important and in some cases new runtime related questions:
How are all my microservices configured and is it correct? Handling configuration is not a major issue with a few applications, e.g. each application stores its own configuration in property files on disk or configuration tables in its own database. With a large number of microservices deployed in multiple instances on multiple servers this approach becomes trickier to manage. It will result in a lot of small configuration files/tables spread all over the system landscape making is very hard to maintain in an efficient way and with good quality.
What microservices are deployed and where? Keeping track of what host and ports services are exposed on with a few number of applications is simple due to the low numbers and a low change rate. With a large number of microservices that are deployed independently of each other there will be a more or less continuous changes in the system landscape and this can easily lead to a maintenance nightmare if handled manually.
How to keep up with routing information? Being a consumer of services in a dynamic system landscape can also be challenging. Specifically if routing tables, in for example reverse proxies or the consumers configuration files, needs to be updated manually. Basically there will be no time for manual editing of routing tables in a landscape that is under more or less constant evolution with new microservices popping up on new host/port addresses. The delivery time will be far too long and the risk for manual mistakes will risk quality aspects and/or make the operations cost unnecessary high.
How to prevent chain of failures? Since the microservices will be interconnected with each other special attention needs to be paid to avoid chains of failure in the system landscape. E.g. if a microservice that a number of other microservices depends on fails, the depending microservices might also start to fail and so on. If not handled properly large parts of the system landscape can be affected by a single failing microservice resulting in a fragile system landscape.
How to verify that all services are up and running? Keeping track of the state of a few applications is rather easy but how do we verify that all microservices are healthy and ready to receive requests?
How to track messages that flow between services? What if the support organization starts to get complaints regarding some processing that fails? What microservice is the root cause of the problem? How can I find out that the processing of, for example, order number 12345 is stuck because microservice A is not accessible or that a manual approval needs to be performed before microservice B can send an confirmation message regarding that order?
How to ensure that only the API-services are exposed externally? E.g. how do we avoid unauthorized access from the outside to internal microservices?
How to secure the API-services? Not new or specific question related to microservices but still very important to secure the microservices that actually are exposed externally.
To address many of these questions new operations and management functionality is required in a system landscape not required, or at least not to the same extent, when only operating a few applications. The suggested solution to the questions above include the following components:
Central Configuration server Instead of a local configuration per deployed unit (i.e. microservice) we need a centralized management of configuration. We also need a configuration API that the microservices can use to fetch configuration information.
Service Discovery server Instead of manually keeping track of what microservices that are deployed currently and on what hosts and ports we need service discovery functionality that allows, through an API, microservices to self-register at startup.
Dynamic Routing and Load Balancer Given a service discovery function, routing components can use the discovery API to lookup where the requested microservice is deployed and load balancing components can decide what instance to route the request to if multiple instances are deployed for the requested service.
Circuit Breaker To avoid the chain of failures problem we need to apply the Circuit Breaker pattern, for details see the book Release It! or read the blog post Fowler - Circuit Breaker.
Monitoring Given that we have circuit breakers in place we can start to monitor their state and also collect run time statistics from them to get a picture of the health status of the system landscape and its current usage. This information can be collected and displayed on dashboards with possibilities for setting up automatic alarms for configurable thresholds.
Centralized log analysis To be able to track messages and detect when they got stuck we need a centralized log analysis function that is capable to reaching out to the servers and collect the log-files that each microservice produce. The log analysis function stores this log information in a central database and provide search and dashboard capabilities. Note: To be able to find related messages it is very important that all microservices use correlation id’s in the log messages.
Edge Server To expose the API services externally and to prevent unauthorized access to the internal microservices we need an edge server that all external traffic goes through. An edge server can reuse the dynamic routing and load balancing capabilities based on the service discovery component described above. The edge server will act as a dynamic and active reverse proxy that don’t need to be manually updated whenever the internal system landscape is changed.
OAuth 2.0 protected API’s To protect the exposed API services the OAuth 2.0 standard is recommended. Applying OAuth 2.0 to the suggested solution results in:
Note: Over time the OAuth 2.0 standard will most probably be complemented with the OpenID Connect standard to provide improved authorization functionality.
All together this means that the microservices need a infrastructure with a number of supporting services as described above that the microservices interact with using their API’s. This is visualized by the following picture:
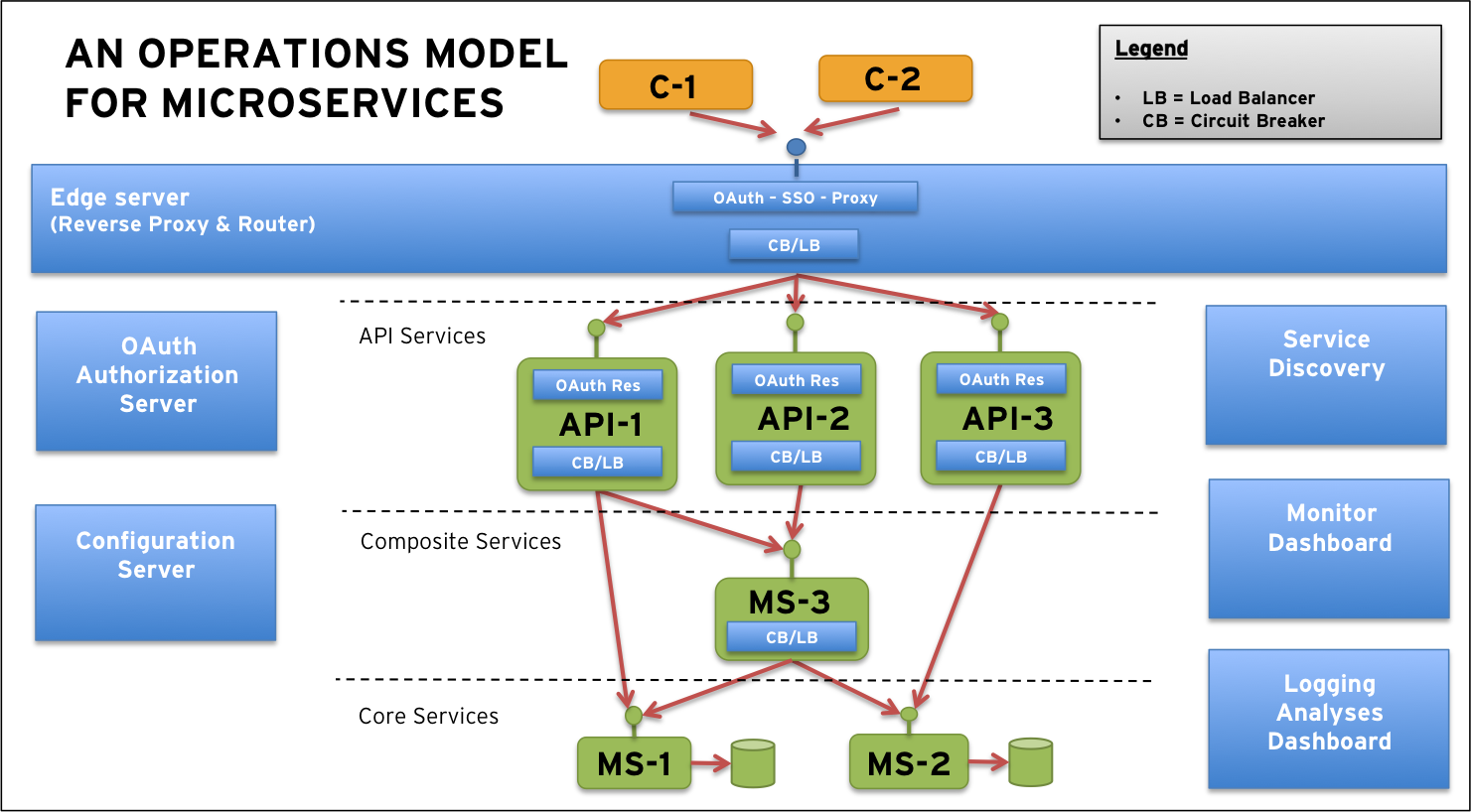
Note: To reduce complexity in the picture interactions between the microservices and the supporting services are not visualized.
In upcoming blog posts we will describe and demonstrate how the suggested reference model can be implemented, see the Blog Series - Building Microservices.