Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

This blog post is not about Star Trek Borg, but instead about Google Borg, Google’s internal large-scale container-oriented cluster-management system, and its open source based successor Kubernetes. Google presented its new tool for orchestrating and managing Docker containers at scale, Kubernetes, at SpringOne2GX.
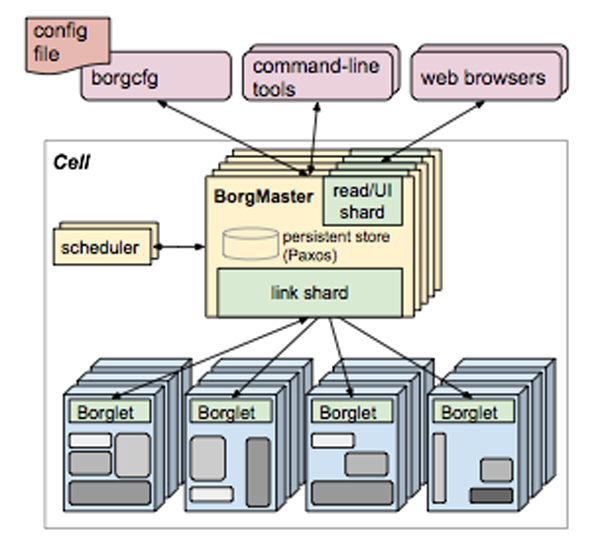
In the presentation at SpringOne2GX we learnt that Google has been running containerized workloads in production for over ten years. Everything at Google runs in containers and today they launch over 2 billion containers per week (that’s a lot of containers to me!). To handle this type of workload Google has built Borg, a cluster manager that runs hundreds of thousands of jobs, across a number of clusters each with up to tens of thousands of machines. In April 2015 Google revealed information about Borg, read more about it in Google’s research paper Large-scale cluster management at Google with Borg. The architecture of Borg is summarized in the paper by the following picture:
Back in 2014, Google started to work on a open source version of Borg, known as Kubernetes. In July, v1 was released. Kubernetes is an open-source platform for for orchestrating and managing Docker containers, automating deployment, scaling, and operations of application containers across clusters of hosts. See the blog post Kubernetes: Open Source Container Cluster Orchestration for an introduction. The presentation at SpringOne2GX contained the following architectural overview of Kubernetes:
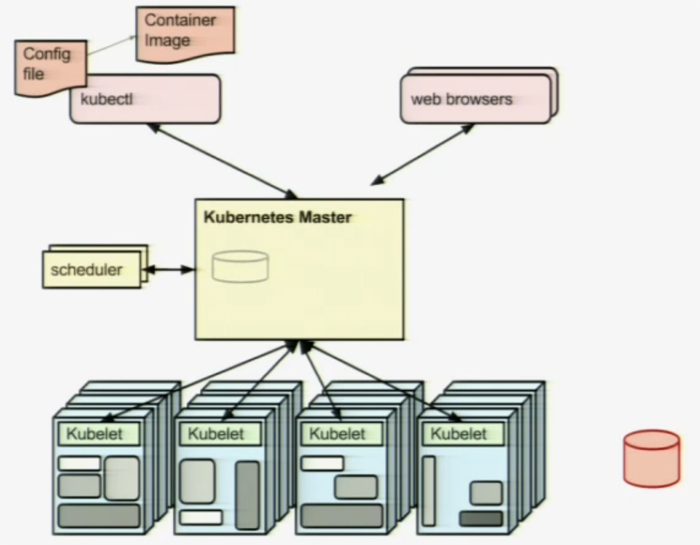
As you can see Kubernetes has its similarities with Borg. One difference is the database in the lower right corner in the Kubernetes picture. It illustrates some kind of registry for Docker images, e.g Docker Hub.
Google did a couple of very cool demonstrations during the presentation. First they demonstrated manually scaling up a number of pods (a pod runs one or more colocated Docker containers) with a command like:
kubectl scale rc "name" --replicas="n"
In the demo Google scaled up from two pods to four pods and it was visualized in a user interface like:
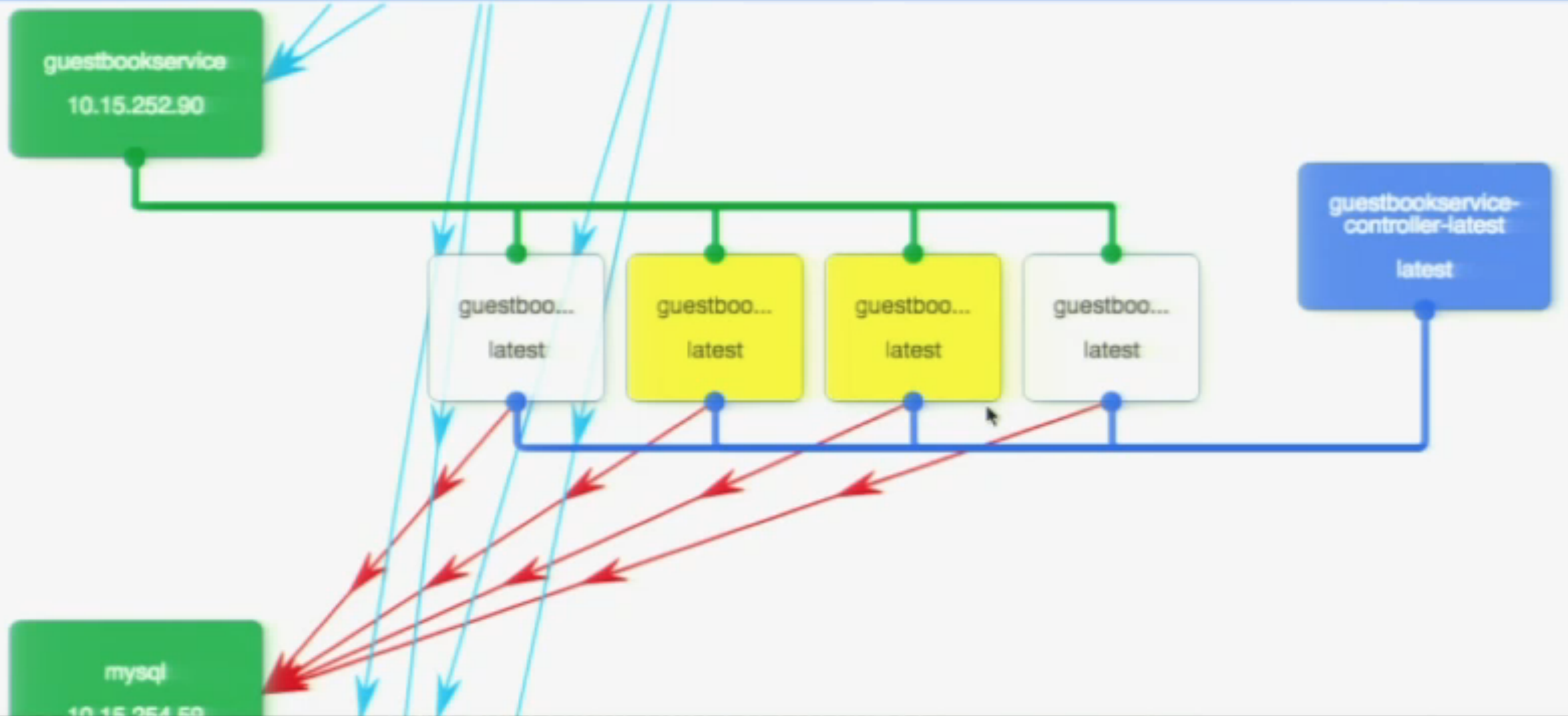
In the picture above we can see two new pods (the yellow ones) starting up. After a few seconds they turned into white, i.e. they were operational and ready to receive request form the load balancer.
The second demo was about zero downtime deployment and automatically perform a rolling upgrade of an application (or microservice if you prefer ;-), a.k.a blue-green deployment. The upgrade was initiated by a command like:
kubctl rolling-upgrade "name" --update-period="wait-time""
Note: The wait-time parameter can be used to wait some time between the updates of each instance, e.g. give some time to ensure that everything works as expected before upgrading the next instance…
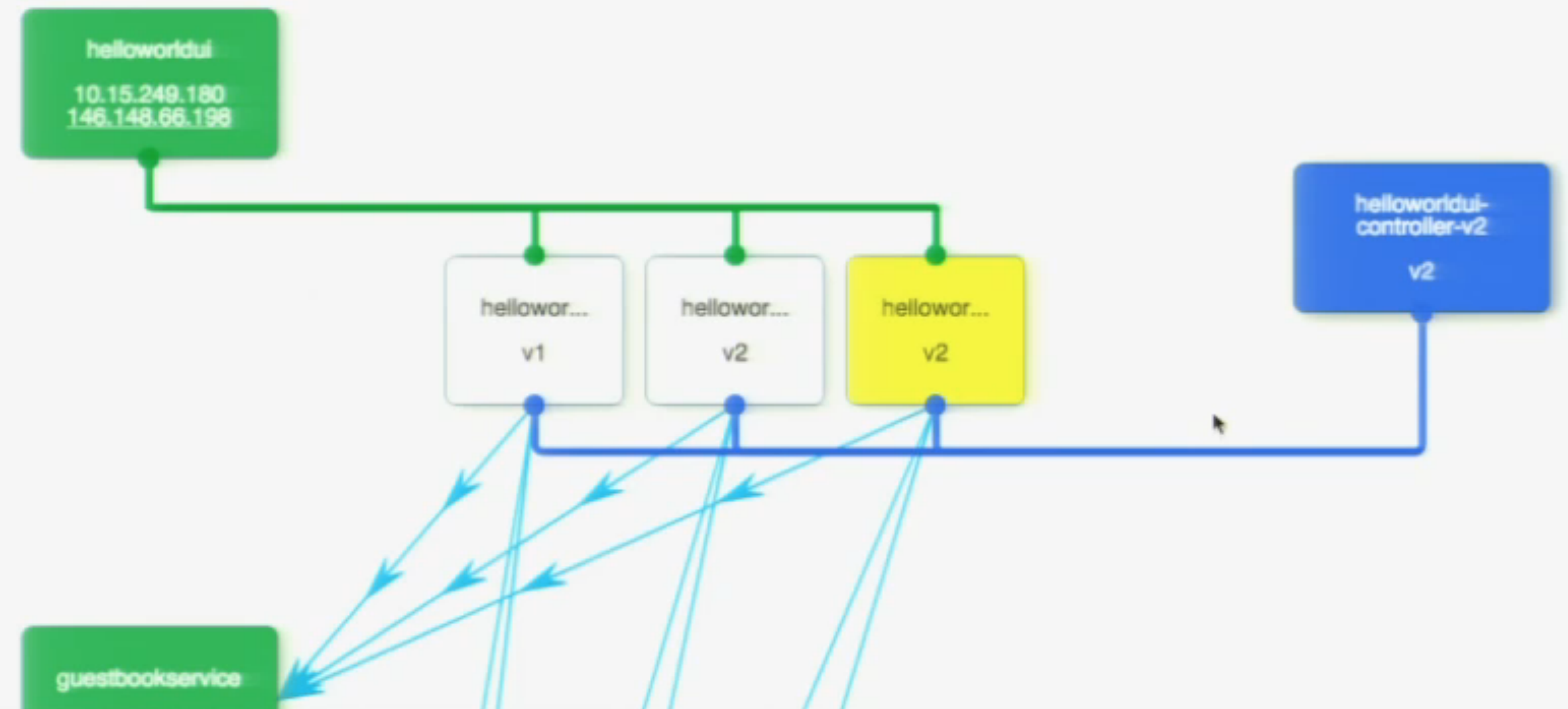
The screenshot below shows the point in time where the first instance (of two) already has been updated to v2 and the second v2 instance in on its way up (therefore in yellow). Once the second v2 instance is operational the remaining v1 instance will be shut down and the upgrade is complete. The load balancer was, of course, automatically updated during the process. The applications web user interface was used during the upgrade process to prove zero downtime.
If you find this interesting you should try it out, it’s very easy!
The easiest way to run Kubernetes is on Google Container Engine but is can also be installed either in the cloud (e.g. on Google Compute Engine, Amazon Web Services or Microsoft Azure) or on premises (e.g. directly on various Linux distributions or on Mesos or VMware vSphere). You can also install it locally on your developer machine using Vagrant and your favorite virtualization software (VMware Fusion, Parallels or VirtualBox). See Getting Started for details.
I tried it out locally on Vagrant and VirtualBox and it was a no-brainer to get my first Kubernetes cluster up and running, prepared to scale and manage Docker Containers!
Once I’ve got time to deploy, run and scale some co-operating Docker Containers on Kubernetes I’ll be back and report my findings.
Stay tuned!