Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

In yesterday’s blog post, I summarized my experience from the first day of the Spring XD tutorial. In this blog post I’ll try to wrap things up regarding the tutorial and the subject at hand.
Spring XD jobs, Hadoop integration and distributed execution was the topics for today and as a bonus we also had time to take a peek at the runtime analytics functionality.
First off, the batch jobs presentation offered some insight into how streams and jobs can be used to orchestrate data flows. Spring XD jobs are just Spring Batch under the hood and one lab exercise was to develop a custom Spring Batch job and deploy it as a module into Spring XD. Regrettably, it wasn’t really development - it was plain copy/paste from examples and I guess most students finished within 5-10 of the allotted 30 minutes. An all-too common case during these two days.
The most time-consuming action of the day was definitely setting up Hadoop on our local machines. Suddenly we were installing ssh daemons, fiddling with keys and modifying configuration files in a number of places. However, the actual lab was just as trivial as before - a 4-line .csv file was read by a filepollhdfs job and copied into the hadoop filesystem. The actual “lab” part took about 30 seconds to implement and test, getting hadoop set up probably took another 30 minutes. Some students still hadn’t gotten hadoop running when the tutorial concluded a few hours later.
Another somewhat time-consuming action was getting Spring XD running in its fully distributed mode of operation. That required standalone installations of Redis, ZooKeeper and HSQLDB, some configuration changes to the servers.yml file and finally starting one XD admin process and an arbitrary number of XD container instances. However, this task proved worth one’s while since it gave me the very first genuine “this is cool!” sensation of the tutorial.
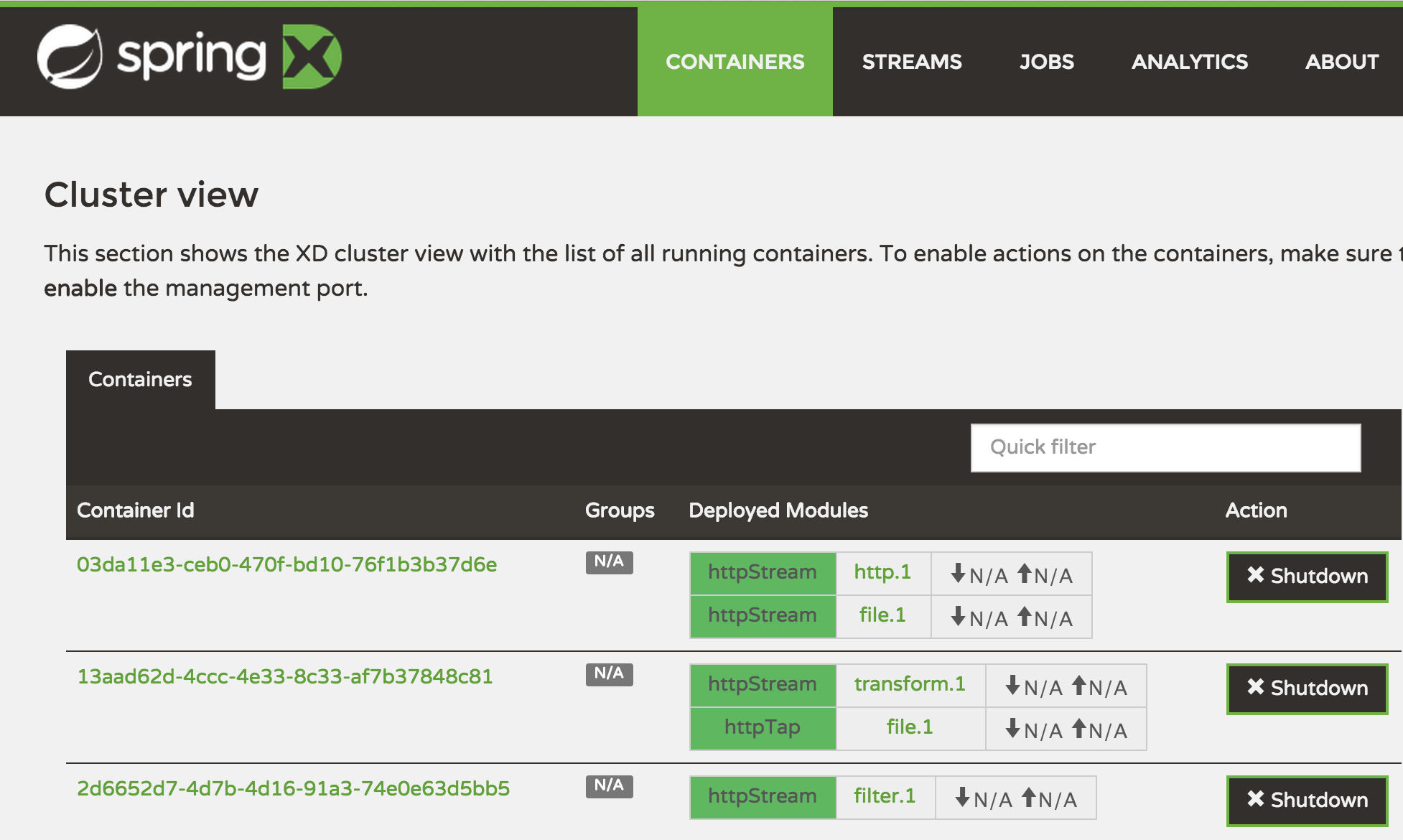
In the screenshot, we see how my three running XD containers have automatically load-balanced the “httpStream” and its four participating modules (http,filter,transform,file) onto the three different containers. Ignore that ‘httpTap’ for now, it’s just a stream that taps the httpStream and redirects its output to a file sink itself.
To make a bit more sense of the stream above, let’s go through the basic DSL for setting up that ‘httpStream’ present in the screenshot:
stream create --name httpStream --definition "http --port=9003 |
filter --expression=payload.contains('1') |
transform --expression=payload.toUpperCase() | file" --deploy
The important thing is the –definition which enclosed inside the quotation marks defines a stream consisting of four modules, using the unix-style pipe character to denote ‘piping’ the result over to the next module:
So, if we do an http POST to localhost 9003 with the Stream above deployed containing a body such as ‘Spring 1 XD’ the file sink will result in the line SPRING 1 XD being written to the httpStream.out file. Banal, but comprehensible.
Anyway, besides from that really awesome automatic load balancing, the failover mechanism is quite sweet too:
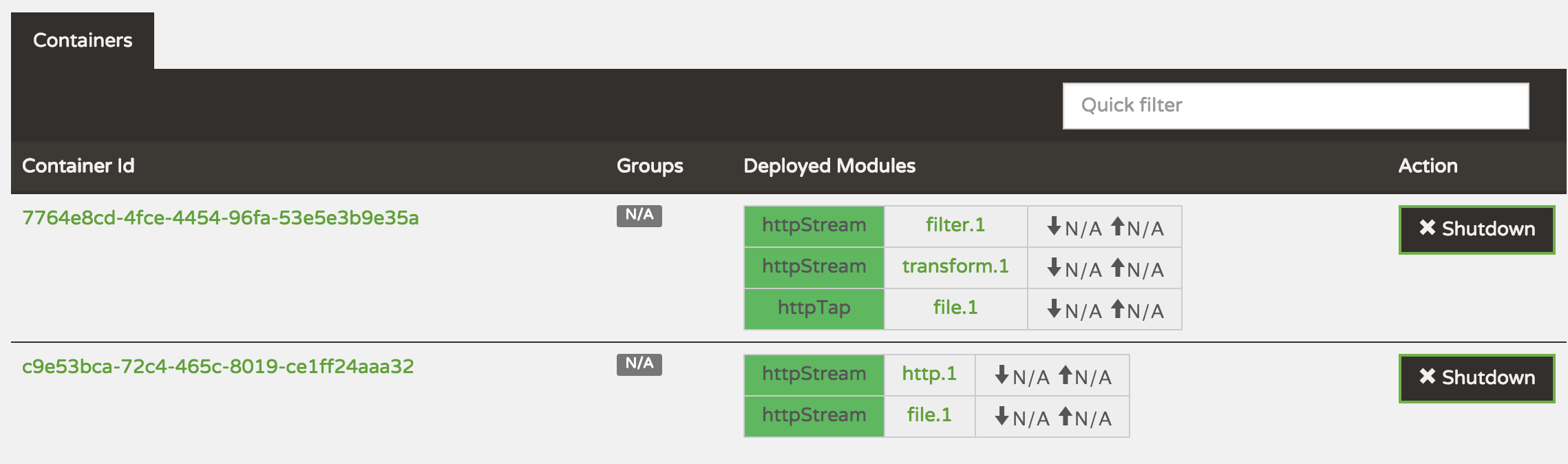
After killing one of the nodes by doing Ctrl+C old-school style in the console window, the second screenshot shows how the XD cluster automatically rebalanced itself on the two remaining XD containers. That happened in a split second thanks to the beautiful job done behind the scenes by ZooKeeper. Well - there were spots on this brightly shining example though - when bringing up the third XD container again, it sat empty and unused until I forcibly redeployed the httpStream. Spring XD doesn’t currently seem to be able to rebalance across XD containers as they become available, only doing so when containers go offline or when deploying streams or jobs.
This distributed scenario described above is definitely where Spring XD really shines. But there doesn’t seem to be any best practices in place on how to actually provision new hosts running XD containers and the required ZooKeeper, RDMBS and Redis/RabbitMQ/Kafka as each participating host must install all of these. That’s likely rather easy to accomplish through virtualization images, chef, puppet, ansible or whatever but a topic not mentioned at all in the tutorial. Also, there were no mentioning at all about how one should manage one’s streams, jobs and taps expressed in the XD DSL or how to manage your custom jobs and processors which are packaged as jar files and uploaded as modules into the XD runtime. Another topic is logging - an enterprise may run scores of Streams and Jobs on an XD cluster, how would one differentiate streams from one another in logs? Are there mechanisms to track a given message in a stream across different XD containers?
From a DevOps point of view, I guess most of these things can be handled but this topic should have been brought up in the 300+ slide presentation.
I’ve previously complained about the trivial nature of the labs of the tutorial. An example lab scenario I would have liked is an incremental development of a complete data ingestion solution over the two days where the full ecosystem leveraging Spring XD eventually would come into play. I’m not talking about sinking some strings to a file, I’m referring to actually performing data ingestion from multiple sources where XD would have to transform, aggregate and sink data to various targets facilitating it for use in related products such as Apache PIG for analysis or perhaps Hive on top of Hadoop. Data simulation can be provided by a pre-made component (for example a Gatling script) capable of simulating huge amounts of diverse data on the fly.
While the scope mentioned above sounds enormous for a 2-day tutorial, having the full stack of required software pre-packaged and configured into a virtualization image greatly reduces time spent on software installs. The actual lab tasks can still be limited in scope but made much more interesting by being more akin to real-life scenarios.
I think these two days spent in the Spring XD tutorial hosted by the Pivotal team was time well spent, though I think there is room for some improvement regarding compacting the presentation material and making the lab scenarios more geared towards how to use Spring XD to solve common real-life uses cases on the architectural level. Spring XD will certainly find traction among many enterprises dealing with Big Data in some way or another given its first-class support for hadoop and scaling abilities. For other applications not dealing with huge amounts of data at high throughput rates, Spring XD might just not be the best tool for the job.