Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

Lyssnade på Per-Åke Minborg, CTO Speedment på javaforum igår. En intressant presentation av deras ORM.
Det handlar om att hela innehållet i en traditionell relationsdatabas (planeras stöd även för NoSQL-produkter som tex Mongo) läses in i minnet. Vår egen applikationen jobbar sedan mot de objekt som ligger i minnet. Allt är skrivet i Java 8 och man måste använda Java 8 också. Java 8 streams-api:et används för att filtrera och söka bland det som man kallar Materialized Object View som typisk kan vara en map med objekt som motsvarar en tabell.
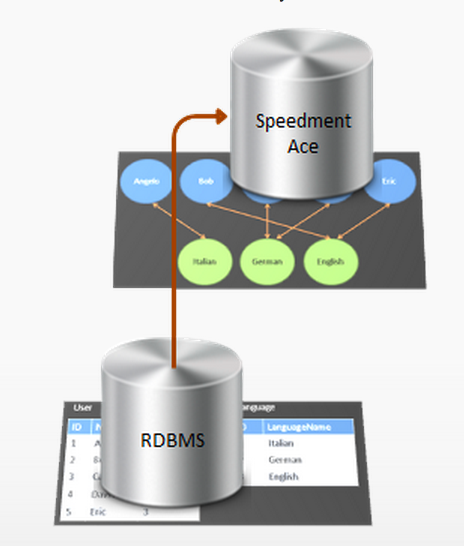
Man använder CQRS-mönstret (ständigt denne Fowler :-) för att separera läs och skrivoperationer och skrivningar hamnar “eventually” i databasen. Det sades att fördröjningen inte var speciellt stor men den fanns där. Databasen skall alltid varit i ett konsistens läge enligt Per-Åke också.
Baserat på dessa egenskaper utlovades prestanda vara i närheten av ljushastigheten jämfört med remote-anrop till en traditionell databas.
Vad betyder det att objekten ligger i minnet ? Ja det måste inte vara RAM utan kan även vara tex en SSD. Tanken är att organisera data så att de hetaste tabellerna ligger i RAM och sedan organisera i olika typer av minne beroende på access-frekvens. Om man har extremt stora datamängder så finns en option att jobba med hazelcast vilket sågs som en samarbetspartner.
Om man skall börja använda produkten så pekar man ut en databas. Speedment genererar sedan ORM-kod för databasen. Därefter är det bara att börja skriva sin egen kod. Den genererade koden är proprietär (att uppfylla JPA skulle bli för långsamt ) och den kod man ser är nästan alltid interface vilket framhölls som en fördel, dvs inga arvshierarkier.
Man håller på att opensource produkten i samband med att en total omskrivning från en äldre java7-baserad version. Företaget var på på väg mot silicon valley.
Några nackdelar ? Ja vid omstart tar det ju lite tid att läsa upp hela databasen, men tanken var ju att använda flera servrar och starta om en i taget.
Fick ett lite rörigt intryck map gamla och nya versionen och stängd kontra öppen källkod. Men det verkar som man har ett visst momentum. Om man ändå har tänkt sig göra en hemmasnickrad CQRS-lösning så kan det nog vara vettigt att titta på Speedment där man verkar får ganska mycket färdigt direkt i lådan.