Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

För många år sedan ställde en amerikansk forskare vid namn Mary Shaw en intressant frågeställning. Hur kommer det sig att en del projekt lyckas och andra misslyckas trots att förutsättningarna egentligen är likadana? Hon kom fram till att det inte är så lätt att se en gemensam faktor för de projekt som misslyckas. Men hon kunde tydligt urskilja ett antal saker som genomgående framträdde i lyckade projekt.
Något som ofta återkom i lyckade projekt var en tydlig uppdelning i mjukvaran för olika ansvarsområden. Det kunde röra sig om klienter som använde en gemensam server där själva applikationen körde. Det handlade ofta om en tydlig uppdelning av det som visas på skärmen i förhållande till de delar av applikationen som koordinerar att saker händer och den underliggande datastrukturen. Andra saker hon såg var sekventiella skeden där en mängd information kommer in till en modul som hanterar den och sedan skickar den vidare till nästa modul. Allt med en tydlig och skarp gräns för ansvarsområde för varje modul.
Det Mary Shaw upptäckte redan tidigt gav hon namnet arkitekturmönster. De saker som nämnts ovan som hon identifierade är exempel på sådana mönster och de har namnen Client-Server, Model-View-Controller (MVC) och Pipes and Filter. Det finns ganska många arkitekturmönster och dessa tre utgör bara några exempel.
Nu vill jag inte leda någon till att tro att bara för att man använder arkitekturmönster så blir projektet lyckat. Snarare vill jag säga att om du inte använder dem är sannolikheten stor att projektet inte blir lyckat. Dessutom är många av de här mönstren så invanda i vårt sätt att tänka så många av dem har du troligen stött på tidigare utan att tänka på dem som mönster.
Men vad menar vi då med ordet mönster i det här fallet? Om du tänker dig en tapet med olika mönster i så ser du att samma saker uppträder om och om igen längs väggarna i rummet. Det är precis just den upprepningen som det handlar om för arkitekturmönster också. Om och om igen så används Model-View-Controller, Client-Server, Pipes and Filter eller något annat arkitekturmönster i olika applikationer. Mönster är därför ett bra ord för att beskriva det hela på.
Om vi backar tillbaks ett par steg till tidigare inlägg i bloggserien så har vi sett att utan krav på kvalitet så kan man i princip lägga all kod i en enda stor modul utan någon inre struktur. Här säger vi att mönster handlar om att ha flera olika moduler med tydliga ansvarsområden. Det är så långt bort som det går att komma från att lägga all kod i en enda stor modul.
Men hur förhåller sig då mönster och taktiker i förhållande till varandra? Det som vi säger här om att inte lägga all kod i samma modul och om att uppnå kvalitetsegenskaper stod även i förra bloggen. Men den handlade om taktiker inte om mönster. För att få svar på den frågan går vi återigen till ”Software Architecture In Practice, 3rd ed”. På sidan 204 står följande;
“Tactics are the ”building blocks” of design, from which architectural patterns are created. Tactics are atoms and patterns are molecules. Most patterns consist of (are constructed from) several different tactics.”
För att det hela ska bli tydligt behöver vi först titta lite mer på taktiker för att sedan återgå till mönster igen. Den taktik vi tittade på i förra bloggen handlade om kvalitetsegenskapen tillgänglighet och vi kunde se hur taktiker som redundans och ping-echo ledde till införandet av nya mjukvaruelement i arkitekturen. Men de element som infördes (tex en till server, en monitor eller en larmfunktion) var typiska infrastrukturelement. Kvalitetsegenskapen säkerhet leder också ofta till uppdelning i olika typer av infrastrukturelement. En kvalitetsegenskap som däremot på ett mycket direkt sätt handlar om hur du delar upp din kod i olika moduler är modifierbarhet. Modifierbarhet har ”change arrives” som input och mäts i hur lång tid det tar för ett utvecklingsteam att göra en förändring av en viss storlek. Här följer en beskrivning på taktiker för att uppnå hög grad av modifierbarhet.
Den här kategorin handlar om att dela upp koden i ett antal mindre moduler. Om en modul kan göra väldigt många saker kommer den troligen också att vara dyr från ett modifierbarhetsperspektiv.
Den här kategorin handlar om att få moduler att vara mer fokuserade inom ett specifikt ansvarsområde. Om en modul ansvarar för flera ansvarsområden kan det vara bättre att dela upp den i olika moduler som var och en ansvarar för olika ansvarsområden.
Den här kategorin handlar om att minska behovet av direkta kopplingar mellan moduler. Om en modul anropar en annan så kan den heller inte fungera utan att den andra modulen finns och har därför ett beroende till den.
Den här kategorin handlar om att så sent som möjligt koppla ihop saker. Det kan exempelvis handla om att dynamiskt slå upp en tjänst så att den kan användas istället för att bygga in ett hårt beroende till den när man bygger ihop applikationen.
Nu när vi har lite historisk bakgrund till arkitekturmönster och lite mer förståelse för taktiker så befinner vi oss i ett utmärkt läge att titta närmare på några exempel på arkitekturmönster.
Model-View-Controller (MVC)
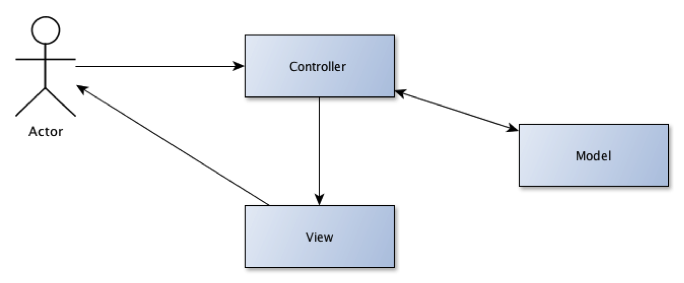
Mönstret MVC handlar om att skilja mellan användargränssnitt och funktionalitet. I en vy så gör en användare vissa val (exempelvis val för att flytta pengar mellan två bankkonton) och efter att användaren till exempel har tryckt på en OK knapp så går en begäran till en controller som är ansvarig för att hålla ihop att det som ska utföras blir korrekt utfört. Controllern utför inte arbetet själv. Den får arbetet utfört genom att arbeta med entitetsobjekt som finns i modellen (bankkonto, kund, belopp osv). När begreppen ”bankkonto”, ”kund” osv skapades kan man säga att man skapade en modell för dessa begrepp. När arbetet med att flytta pengarna har utförts så skapas en ny vy (exempelvis en webbsida) där det står hur det gick att flytta pengarna. Användaren har i den sidan möjlighet att gå vidare och senare utföra flera uppgifter, vilka i sin tur resulterar i att andra controllers blir involverade i att utföra nya saker. På så sätt går MVC flödet runt varv efter varv så länge som användaren (actor i bilden) använder webbsidan eller systemet.
Det är inte nödvändigt att värden ändras för entiteterna i modellen när MVC används. När användaren till exempel gör en sökning så används MVC trots att inget data förändras. MVC har också en fördel att det går att ha olika vyer trots att den underliggande modellen är densamma. Om du använder en Internetbank eller en telefonbank för att flytta pengar mellan två konton så är det ett exempel på just det. Telefonbanken är lika mycket vy (användargränssnitt) som Internetsidorna i Internetbanken är. Men bakomliggande modell är densamma. Dvs samma kod som flyttar dina pengar i din Internetbank kan användas för att flytta dina pengar med en telefonbank.
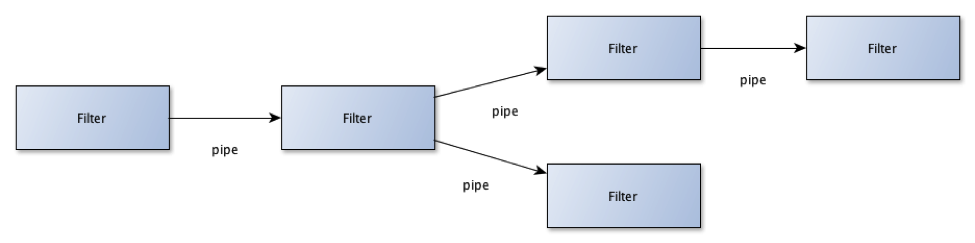
Pipes and filters handlar om att hantera en ström av information där varje filter kan arbeta med och transformera informationen innan det (via en pipe) skickas vidare till nästa filter. Ett scenario kan vara att ett filter krypterar information och ett annat dekrypterar information. Ett annat scenario är ett filter som extraherar betalningsinformation från en XML fil och hanterar betalningen och sedan skickar vidare informationen för nästa steg i en orderhanteringskedja. En ”pipe” kan implementeras på många sätt. Ordet ”pipe” ska här inte tolkas mer strikt än att det är ett sätt att föra vidare information från ett filter till nästa.
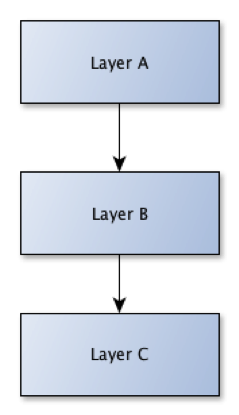
Arkitekturmönstret lagerindelning handlar om att minimera beroenden genom att anrop enbart är tillåtna att utföras nedåt i en struktur av lager som innehåller kodmoduler. Om det fanns kod i alla tre lagren ovan som gör anrop till kod i de andra lagren utan någon restriktion så uppnås lätt det som kallas för ”spaghettikod”. Då är det svårt att ändra någonting eftersom det får påverkan överallt som måste hanteras. Därför är mönstret lagerindelning bra för att förhindra detta och för att få en bättre struktur på koden.
I en lagerstruktur är det naturligt att mer generell kod hamnar längre ned i lagerindelningen och mer applikationsspecifik kod hamnar högre upp. Kodmoduler som implementerar början på användningsfall eller användargränssnitt har också en tendens att hamna högre upp.
Syftet med varje lager är att bära upp lagret ovanför. Om du vill återanvända din kod till att bygga en till applikation går det alldeles utmärkt att ta lager C och börja bygga på det. Men du kan inte bara ta lager A eller lager B och börja bygga på dem utan att även ta med de lager som ligger under dem. Så lagerindelning och att hålla rätt på beroenden har även effekt på de möjligheter som finns till återanvändbarhet.
Nu har vi kommit till ett läge där det tydligare går att förstå vad ”Software Architecture In Practice” menar med sitt uttalande om att de flesta mönster är uppbyggda av taktiker och förhåller sig till dem som molekyler förhåller sig till atomer. Du som har tillgång till boken kan gärna titta på sidan 240 där det även illustreras med en bild som visar vilka taktiker för modifierbarhet som är inbyggda i några av de vanligaste mönstren. Har du inte det så gör det inte så mycket för här följer en beskrivning av det hela.
Alla mönster som vi tittat närmare på ovan har taktiken ”Increase semantic coherence” inbyggd. Hur kan vi inse att det är på det sättet? Det är för att uppdelningen i olika moduler i sig handlar om att få modulerna att fokusera mer på ett enskilt ansvarsområde. Separation av användargränssnitt från själva funktionaliteten och separation av ansvarsområden inom ett informationsflöde till olika filter leder båda till ökat fokus på ett ansvarsområde för varje enskild modul. På samma sätt leder uppdelningen i olika lager till ökat fokus på ansvarsområde.
Mönstren Layered och Pipes and filter (men inte MVC) har taktiken ”restrict communication paths” inbyggda i sig. Lagerindelning har det eftersom anropen alltid går neråt och Pipes and filters har det för att man på förhand vet vilka filter som är efterkommande i kedjan.
Kanske är det viktigaste att ta till sig i den här frågan just det att taktiker och mönster inte är två olika konkurrerande sätt att se på hur man får bra kvalitetsegenskaperna på mjukvaran. Snarare är det så att om du använder arkitekturmönster så har du indirekt (utan att kanske ens veta om det) använt ett antal taktiker. Alla taktiker täcks inte in av mönster så du bör absolut inte lägga taktikerna åt sidan för att enbart arbeta med mönster.
Taktiker är dessutom ofta på lägre nivå än mönster och det finns inget mönster som direkt får dig att inse att redundans eller ping-echo (bara för att ta ett par exempel) är bra taktiker för att uppnå tillgänglighet.
I början av den här bloggen nämnde jag att det var många år sedan som begreppet arkitekturmönster togs fram. Med tanke på den snabba utveckling som sker inom IT så är det naturligt att ställa frågan hur relevanta de här mönstren är idag. De är väldigt aktuella och det går att motivera enkelt på följande sätt.
För det första så beskrivs mönstren grundligt i moderna arkitekturböcker. Software Architecture In Practice 3rd,ed kom ut 2013 och den går grundligt igenom alla taktiker och mönster. Dessutom så är mönstren teknikoberoende så de behöver inte uppdateras bara för att nya programmeringsspråk och tekniker tas fram. En hel del nya mönster (och taktiker) kommer kontinuerligt och ofta handlar det om varianter av sedan gammalt identifierade mönster. Ett exempel på detta är mönstret som kallas för Model-View-ViewModel som är en variant av MVC mönstret.
För det andra så är de här mönstren så grundläggande i förhållande till modern teknik så man kan göra en jämförelse med en skottkärra och en dator. Den dator som jag har på mitt skrivbord hemma är många tusen gånger snabbare än den dator jag hade när jag var student vid Uppsala universitet. Men en skottkärra idag ser i princip ut som en skottkärra såg ut redan på 1800-talet. Skillnaden är att skottkärran är en enkel uppfinning som uppfyller sitt syfte så väl så att den inte har haft behov av att utvecklas vidare vilket datorn har behövt. Så jag ser mönstren på samma sätt som skottkärran. De är så fundamentala och grundläggande så de har inte samma behov av att utvecklas som mycket annat har inom IT.
För det tredje så ser man direkt på modern mjukvaruarkitektur hur de här mönstren och taktikerna används och kombineras för att få fram moderna sätt att bygga mjukvaruarkitekturer på. Det är till exempel enkelt att inse hur taktikerna för att uppnå modifierbarhet är relevanta för arkitekturstilen microservices.
I nästa blogg kommer vi att titta närmare på två andra sorters mönster. Integrationsmönster och designmönster. I samband med det finns det även anledning att titta lite närmare på den roll som arkitekten har.