Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

A major challenge in a distributed system (e.g. a system landscape of microservices) is to understand what is going on and even more importantly – what is going wrong, where and why. In this blog post we will see how we can use the ELK stack (i.e. Elasticsearch, Logstash and Kibana, ) from Elastic to aggregate log events from our microservices in the blog series - Building Microservices into a centralized database for analysis and visualization.
New components in our test landscape are marked with red borders:
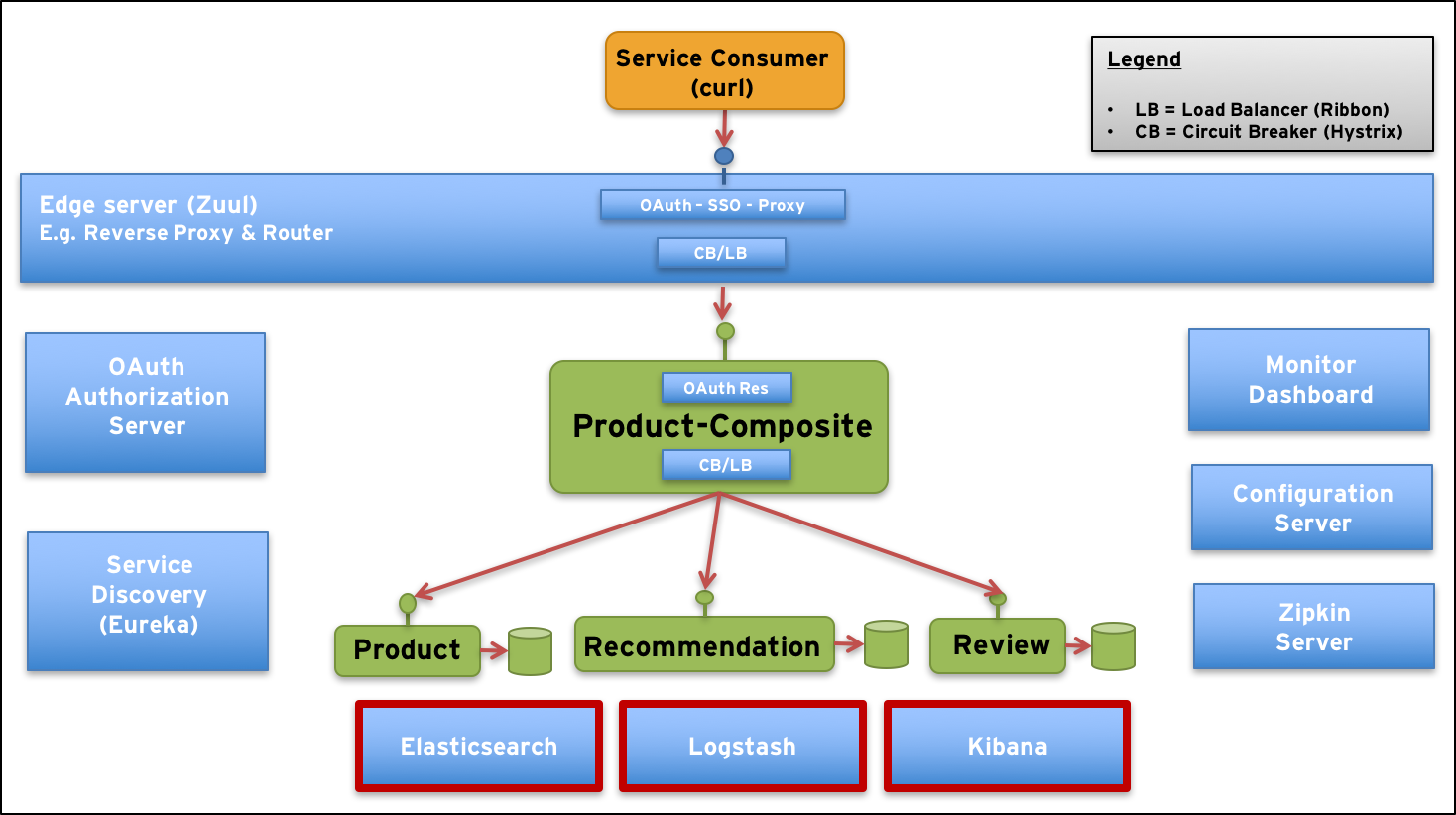
Let’s start with a short description of the new components and some new challenges!
The ELK stack from Elastic consist of:
Logstash
Logstash can collect log events from multiple types of sources using input plug-ins, transform it to a format you prefer using filter and codec plug-ins and send it to a number of destinations using output plug-ins.
Elasticsearch
Elasticsearch is a distributed and scalable full-text search database, that allows you to store and search large volumes of log events.
Kibana
Kibana lets you visualize and analyze your log events stored in Elasticsearch.
Elastic provides official Docker images for Logstash, Elasticsearch and Kibana.
Collecting log events in a container world is not the same as before when we were used to collect log events by tailing log files. That does not work in a containerized world where a container’s file system is ephemeral by default, i.e. it is destroyed if the container crashes. So, for example, after a restart there will be no log file to read log events from to understand what caused the restart. Instead we need to handle log events from containers as an event stream. For more information on the subject see the twelve factor app - treat logs as event streams.
In Docker v1.6.0 (released 2015-04-07) a logging mechanisms called Log Drivers was introduced to handle log events as a stream. A number of formats are today supported out of the box, see supported logging drivers.
When selecting a log driver, we have to match the supported log drivers from Docker with the supported input plugins from Logstash. Both Gelf and Syslog formats are supported by Docker and Logstash. Syslog is an old and restricted standard for log events, something that the newer Gelf format aims to overcome. See Gelf docs for further explanations. Gelf is clearly preferred over Syslog. When using the Gelf format, Logstash does unfortunately not support (from my understanding) multiline log events, e.g. log events with stack traces. For details see discussions here and here. Therefore, we will use the old Syslog format in this blog post.
There are two source code files of interest for enabling the ELK stack:
The source code contains two Docker Compose files:
docker-compose-with-elk.yml,docker-compose-without-elk.yml The shell script setup-env.sh is used to control which Docker Compose file that is in use by setting up the environment variable COMPOSE_FILE:
export COMPOSE_FILE=docker-compose-with-elk.yml
#export COMPOSE_FILE=docker-compose-without-elk.yml
The most interesting new parts of the compose file docker-compose-with-elk.yml are the following:
Adding the ELK stack can, as mentioned above, be done by using official Docker images from Elastic like:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:5.2.2
ports:
- "9200:9200"
environment:
- "xpack.security.enabled=false"
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
kibana:
image: docker.elastic.co/kibana/kibana:5.2.2
ports:
- "5601:5601"
environment:
- "xpack.security.enabled=false"
logstash:
image: docker.elastic.co/logstash/logstash:5.2.2
ports:
- "25826:25826"
volumes:
- $PWD/elk-config:/elk-config
command: logstash -f /elk-config/logstash.config
Note #1: The Docker images comes with a commercial, non free, extension called X-Pack. X-Pack bundles security, alerting, monitoring, reporting, and graph capabilities into one package. X-Pack includes a trial license for 30 days. To avoid dependencies to non-free extensions of the ELK stack we have disabled the X-Pack by setting the environment variable
xpack.security.enabledtofalsefor Elasticsearch and Kibana.Note #2: To reduce the memory used for our test purposes, we have limited the memory usage for Elasticsearch by setting the environment variable
ES_JAVA_OPTSto-Xms512m -Xmx512m.
To be able to capture log events from the startup of our microservices it is important that they don’t start before Logstash is ready to receive log events. In the same way Elasticsearch needs to be up and running before Logstash can start to send log events to Elasticsearch.
Note: In a production environment, we are probably using a container orchestrator like Docker in Swarm mode or Kubernetes. Using a container orchestrator, we can set up Logstash and Elasticsearch as services that, at least conceptually, always are up.
During development, we want to use Docker Compose to start up all containers (both for the ELK Stack and our own microservices) with one command. This leads to that we need to instruct Docker Compose to not start depending containers until the containers they depend on are started and ready to receive requests.
To achieve this we can use:
healthcheck - instructions, to tell Docker runtime how to monitor a container and ensure that it is ok and ready to receive requests.depends_on - instructions, to tell Docker to not start a container until the container it depends on is started. By also specifying the condition service_healthy we ask Docker runtime to wait to start the container until the container it depends on not only is started but also reports that it is healthy (through its health check described above).For the Elasticsearch container we have specified the following health check:
elasticsearch:
...
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9200"]
interval: 10s
timeout: 5s
retries: 10
For Kibana and Logstash we have added a dependency to the Elasticsearch container (to ensure that they are not started until Elasticsearch is ready):
kibana:
...
depends_on:
elasticsearch:
condition: service_healthy
logstash:
...
depends_on:
elasticsearch:
condition: service_healthy
For Logstash we have also specified a health check:
logstash:
...
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080"]
interval: 10s
timeout: 5s
retries: 10
All microservices that wants to send log events to Logstash defines a dependency to Logstash like:
pro:
depends_on:
logstash:
condition: service_healthy
As described above we have decided to use the Syslog driver.
To configure a container to send its log events using Syslog in Docker you can specify something like the following in the Docker Compose file:
logging:
driver: syslog
options:
syslog-address: "tcp://host:port"
Since we gave the Logstash container the name logstash and published the port 25826 you might think that the syslog-address should be set to: "tcp://logstash:25826", but that does not work :-(
The reason for this is that the the Syslog driver is running in the Docker daemon and the Docker daemon can’t access our application’s specific network where the hostname logstash is defined. Instead we can use port-mapping, i.e. expose the Syslog port in the Logstash container in the Docker host. This means that the Docker daemon can address the Logstash Syslog port using the local IP address 127.0.0.1.
So, the configuration looks like this:
logging:
driver: syslog
options:
syslog-address: "tcp://127.0.0.1:25826"
For further details see the following GitHub issue.
Let’s go through the input, codec, filter and output elements in the Logstash configuration file. The source code can be found at elk-config/logstash.config.
Input and codec
input {
http {
port => 8080
type => "healthcheck"
}
syslog {
type => syslog
port => 25826
codec => multiline {
pattern => "^<%{POSINT}>%{SYSLOGTIMESTAMP} %{SYSLOGHOST}\[%{POSINT}\]: %{TIMESTAMP_ISO8601}"
negate => true
what => previous
}
}
}
We accept input from http for the health check declared for Logstash in the Docker Compose file (see §2.1.2 Startup dependencies) and from syslog for the log events. We apply a multiline codec for the log events. The multiline codec is setup to find log events that does not start with a timestamp and consider them as a part of the previous log event. This means that all lines in a stack trace are merged into the log event for the actual error. For details see the Reference Documentation.
Filter
filter {
if [type] == "healthcheck" {
drop {}
}
mutate {
strip => "message"
}
grok {
match => {
"message" => "<%{POSINT:syslog_pri}>%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname}\[%{POSINT:syslog_pid}\]: %{TIMESTAMP_ISO8601:ml_date}(%{SPACE})? %{LOGLEVEL:ml_level} \[%{DATA:ml_service},%{DATA:ml_traceId},%{DATA:ml_spanId},%{DATA:ml_zipkin}\] %{INT} --- \[%{DATA:ml_thread}\] %{DATA:ml_classname} : %{GREEDYDATA:ml_message}"
}
}
if "multiline" in [tags] {
mutate {
gsub => [ "message", "<\d+>.*?:\s", ""]
}
}
mutate {
strip => "ml_thread"
remove_field => [ "level", "version", "command", "created", "message", "tag", "image_id", "severity", "priority", "facility", "severity_label", "facility_label", "syslog_pri"]
}
}
The filter processing does the following:
http input, i.e. health checks.Using a Grok filter we extract and name the parts we are interested in from the log event. Fields in the log event created by syslog are prefixed with syslog_ and fields coming from our microservices are prefixed with ml_.
Note: If you find it hard to get your Grok patterns set up correctly I suggest you try out the Grok debugger!
We collect the following syslog fields (see RFC 3164 for details):
syslog_pri: the PRI part of a syslog messagesyslog_timestamp: the TIMESTAMP part of a syslog messagesyslog_hostname: the HOSTNAME part of a syslog messagesyslog_pid: the PID part of a syslog messageWe collect the following fields from the Java logging framework, Logback:
ml_date: timestampml_level: log levelml_thread: thread idml_classname: name of the logging Java classml_message: the actual message in the log eventWe also collect the following trace information from Spring Cloud Sleuth (see the previous blog post for details):
ml_service: name of the microserviceml_traceId: the trace idml_spanId: the span idml_zipkin: boolean indicating if the span was reported to Zipkin or not<30>Sep 9 06:32:08 89f30c64f36a[1966]: Output
output {
elasticsearch {
hosts => "elasticsearch"
ssl => "false"
user => "logstash_system"
password => "changeme"
}
stdout {
codec => rubydebug
}
}
Log events are sent to:
elasticsearch for storage, to be picked up by Kibanastdout for debugging purposes, using the docker compose logs commandFor details on how to build and run the microservice landscape in this blog post series, see the blog post #5.
Note #1: To be able to run some of the commands used below you need to have the tools cURL and jq installed.
Note #2: Since blog post #5 this blog series is based on Docker for Mac and no longer Docker Toolbox and Docker Machine, that was used in earlier blog posts. If you have Docker Machine installed be sure to run the following command to direct your Docker client tools to work with Docker for Mac:
$ eval $(docker-machine env -u)
In summary:
Open a terminal, create a folder of your choice and cd into it:
$ mkdir a-folder-of-your-choice
$ cd a-folder-of-your-choice
Since we have externalized our configuration into a configuration repository we first need to get it from GitHub:
$ git clone https://github.com/callistaenterprise/blog-microservices-config.git
Next, we get the source code from GitHub and checkout the branch used for this blog post:
$ git clone https://github.com/callistaenterprise/blog-microservices.git
$ cd blog-microservices
$ git checkout -b B11 M11
Now, we can build our microservices with:
$ ./build-all.sh
Finally, we can bring up the dockerized microservice landscape and run a test:
$ . ./test-all.sh start
Note #1: We will not shut down the microservice landscape (can be done by adding the parameter:
stop), since we will use it in the next section.
Note #2: The first
.in the command above is essential. It allows us to reuse theTOKENenvironment variable that the script creates to store an OAuth Access Token, i.e. we don’t need to acquire one ourselves.
After a while, the processing should end with the response from a API request like:
$ curl -ks https://localhost:443/api/product/123 -H "Authorization: Bearer $TOKEN" | jq .
{
"productId": 123,
"name": "name",
"weight": 123,
"recommendations": [ ... ],
"reviews": [ ... ],
"serviceAddresses": { ... }
}
End: Sun Sep 1 13:33:25 CEST 2017
Try a manual call like:
$ curl -ks https://localhost/api/product/456 -H "Authorization: Bearer $TOKEN" | jq .
First verify that Elasticsearch is up and running:
$ curl http://localhost:9200 | jq .
{
"name" : "hK0W3cd",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "KauuQNszTXKOoOdhwgZK6Q",
"version" : {
"number" : "5.2.2",
"build_hash" : "f9d9b74",
"build_date" : "2017-02-24T17:26:45.835Z",
"build_snapshot" : false,
"lucene_version" : "6.4.1"
},
"tagline" : "You Know, for Search"
}
Next verify that we have some indices in Elasticsearch containing data from Logstash:
$ curl http://localhost:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open logstash-2017.09.01 Sv3K6CEyQ2GEl6HtjU3zKQ 5 1 544 3 1.2mb 1.2mb
yellow open .monitoring-kibana-2-2017.09.01 -WfBYJJETTm2qRshojGHBw 1 1 30 0 46.7kb 46.7kb
yellow open .kibana tjoLGboOQxOIpsXPQAiV6g 1 1 1 0 3.1kb 3.1kb
yellow open .monitoring-logstash-2-2017.09.01 NZVw7B7aRjGh4_Pk1Q_hGw 1 1 30 0 51kb 51kb
yellow open .monitoring-es-2-2017.09.01 x7JK10GNRwSqJyq63-Padw 1 1 440 0 709.7kb 709.7kb
yellow open .monitoring-data-2 75Uv2spMTGiz_-qzjfx3dg 1 1 4 0 9.7kb 9.7kb
Finally, we need to configure Kibana a bit:
Open http://localhost:5601 i your web browser. You should see something like:
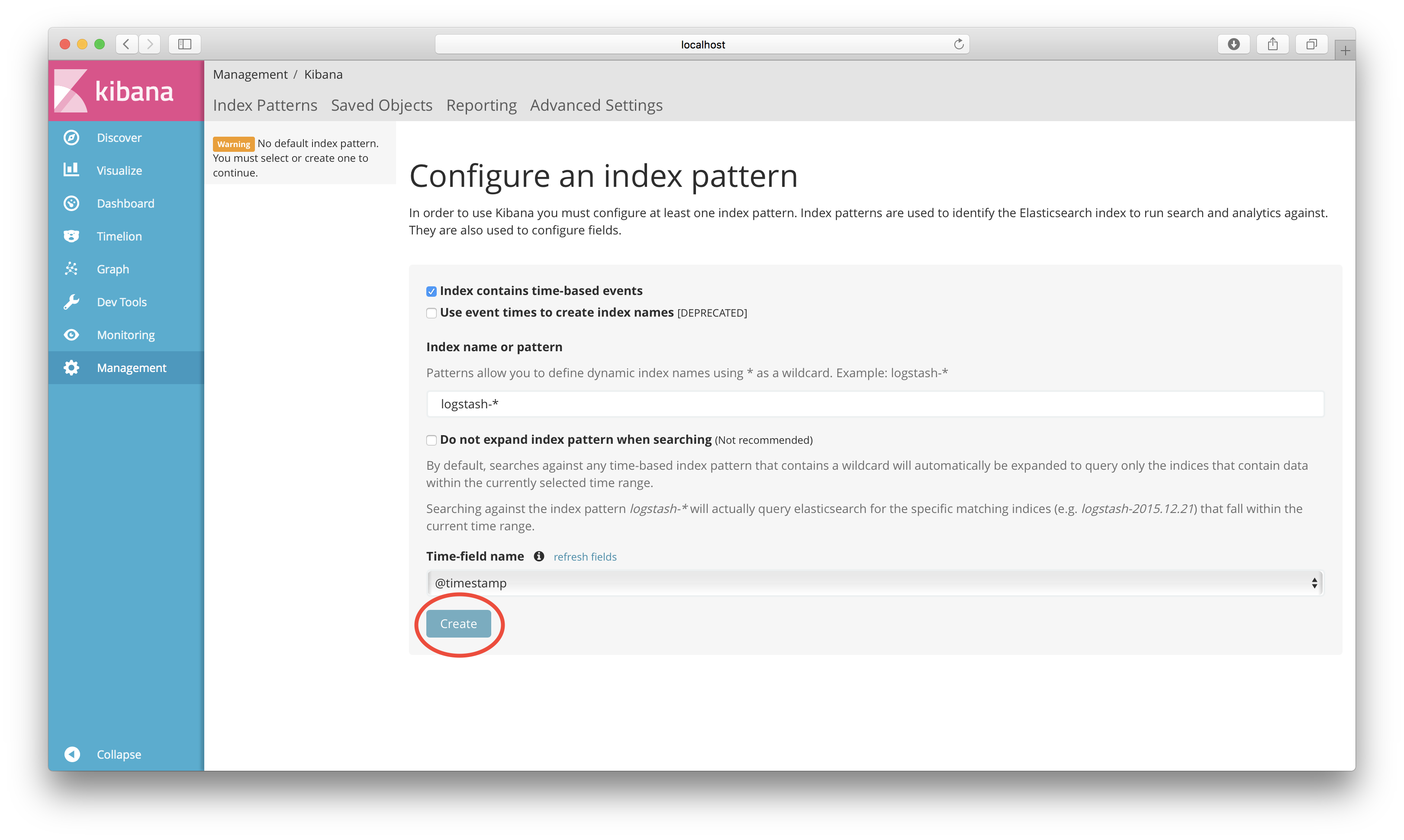
Accept the default values for what index to use and click on the Create button.
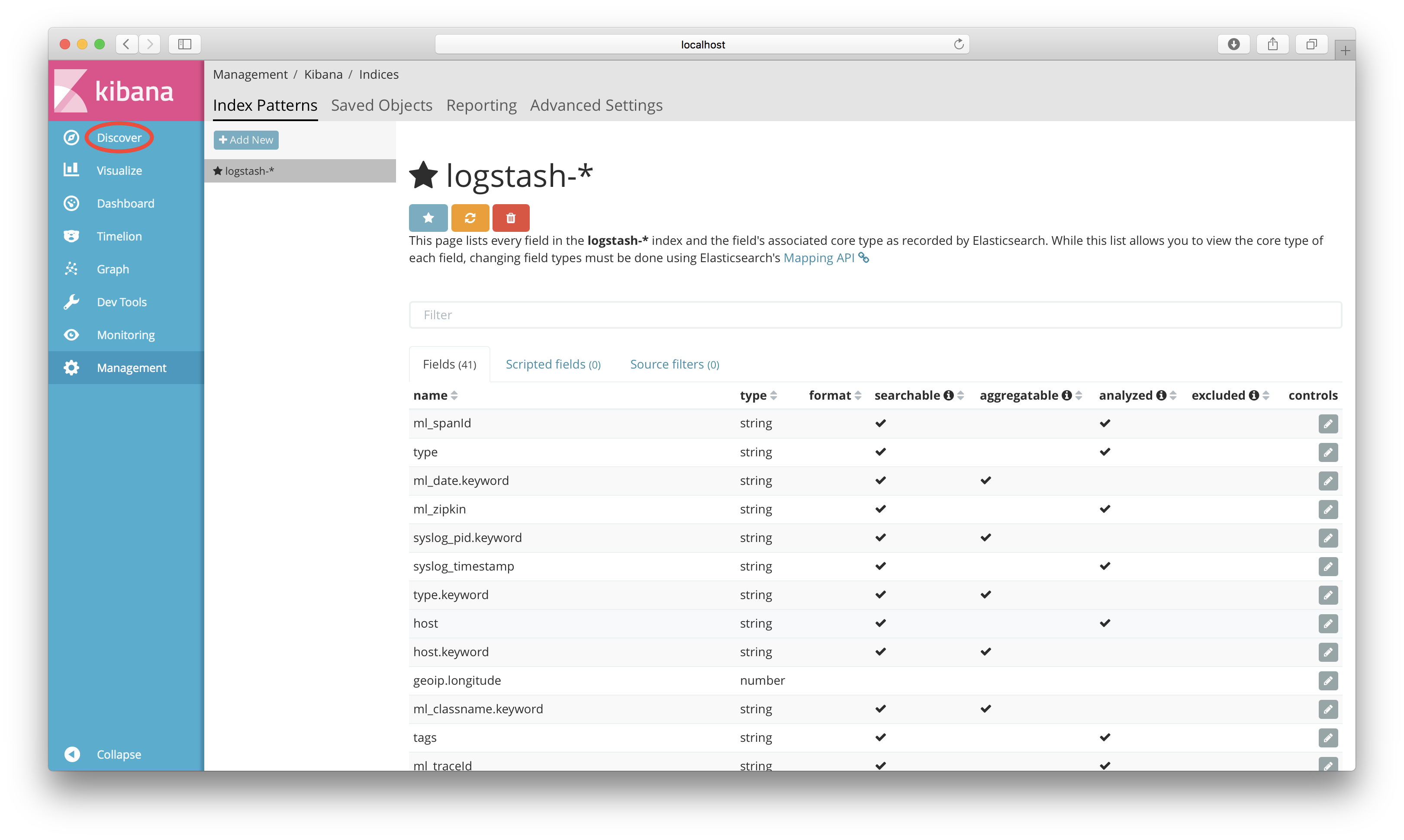
Kibana will now display the fields in the Logstash index. Click on the “Discover” tab in the blue menu to the left.
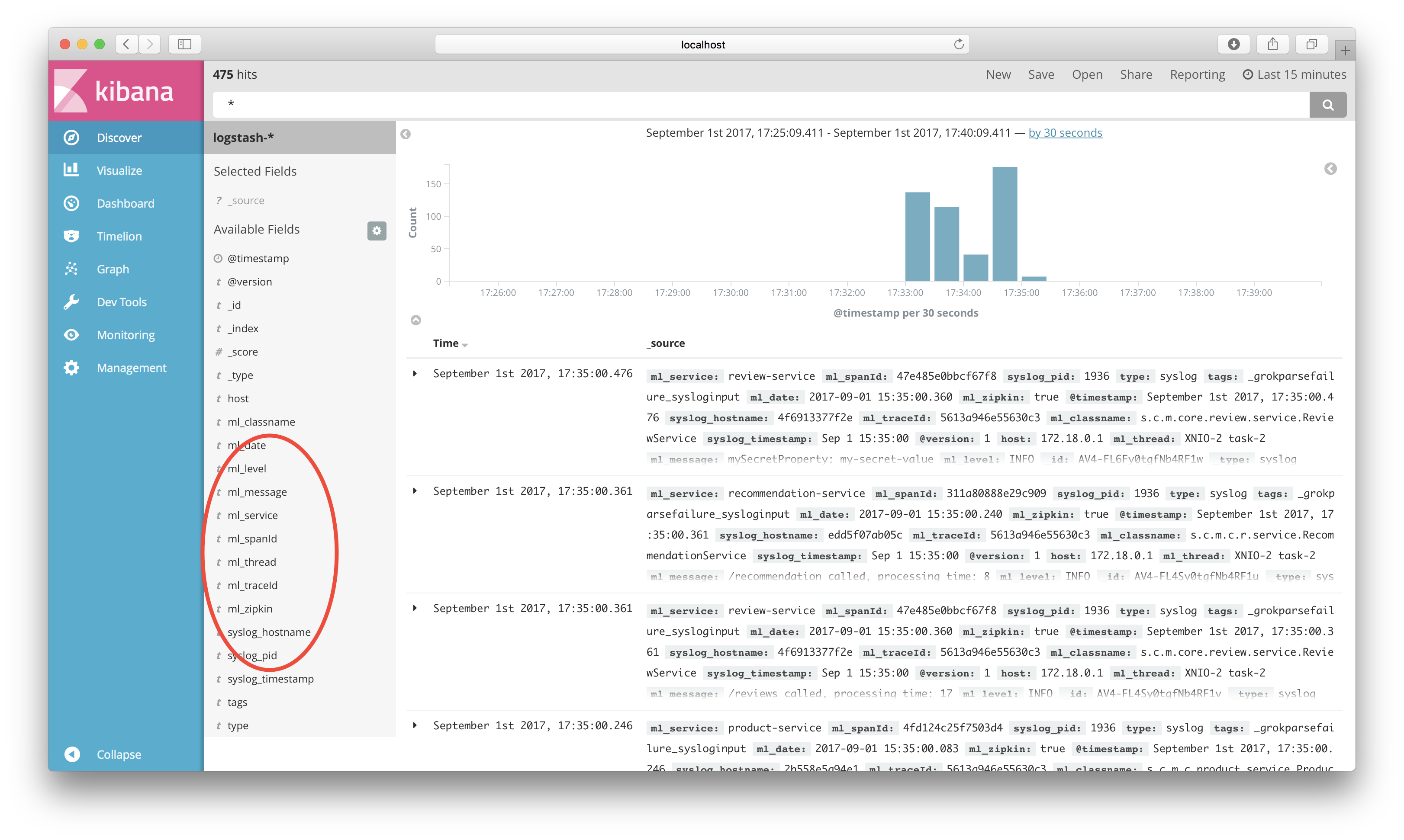
Kibana will now show log events. Select and add the following fields: ml_level, ml_service, ml_traceId, ml_message and syslog_hostname.
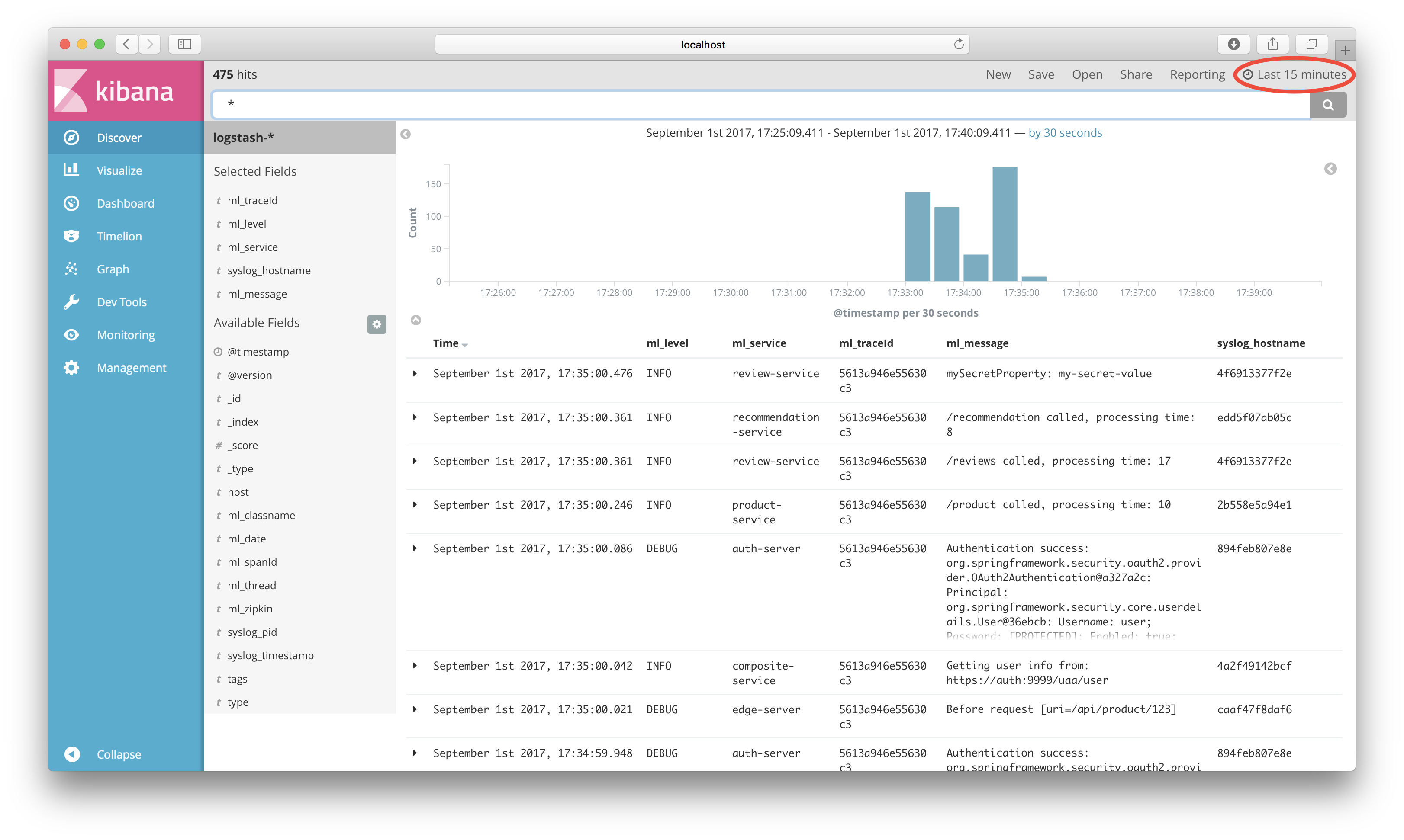
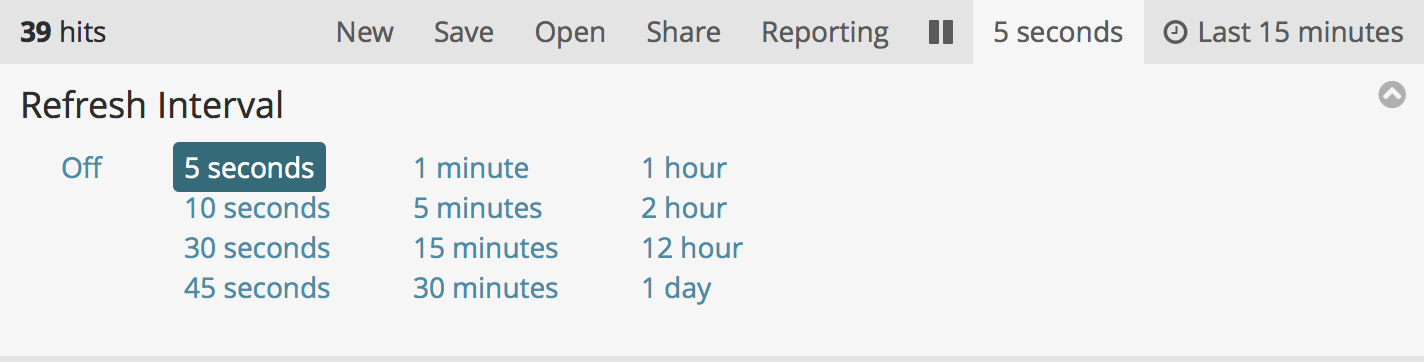
Finally configure the time range and refresh rate to be used by Kibana:
Start to make a request using a unique product number, e.g. 123456:
$ curl -ks https://localhost/api/product/123456 -H "Authorization: Bearer $TOKEN" | jq .
Search for a business key, i.e. the Product Id 123456 in our case:
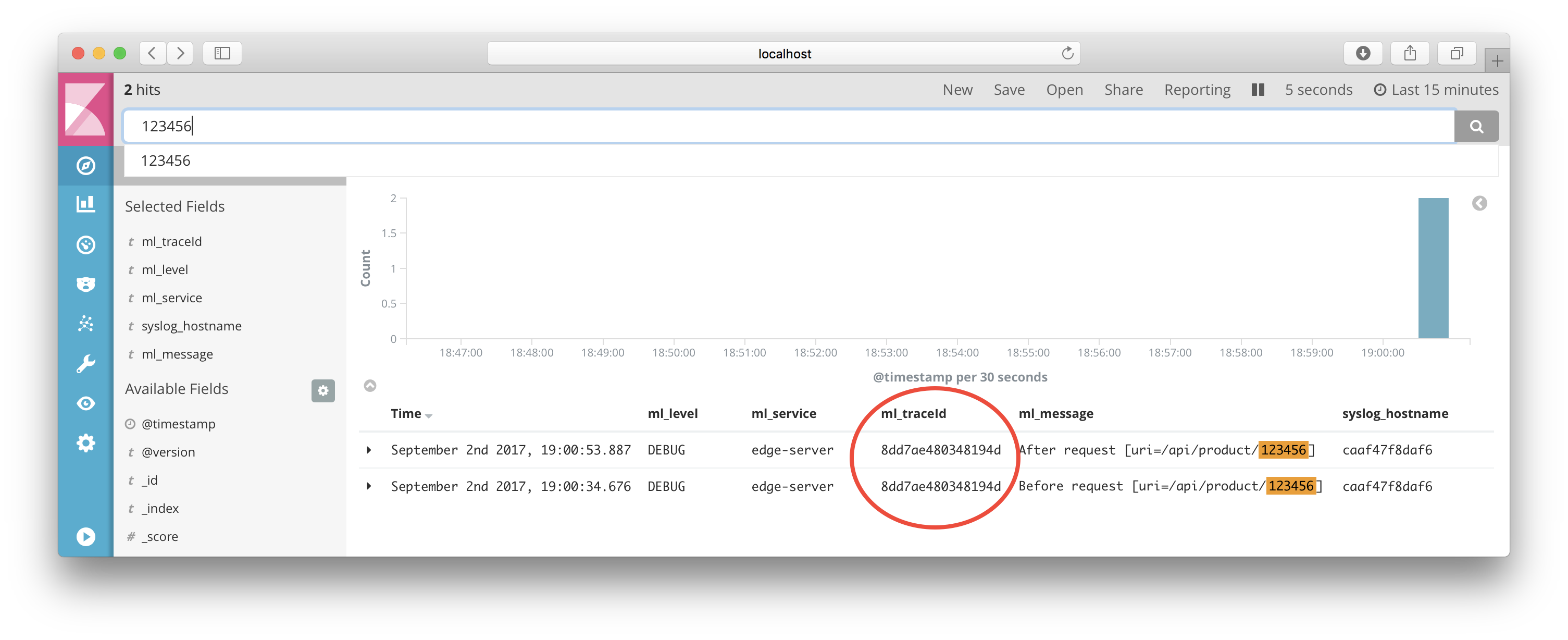
You will find two log events related to this business key. To find all other log events (from all microservices) related to the processing of this business key pick up the value of the ml_traceId (8dd7ae480348194d in my case) and make a new search based on that:
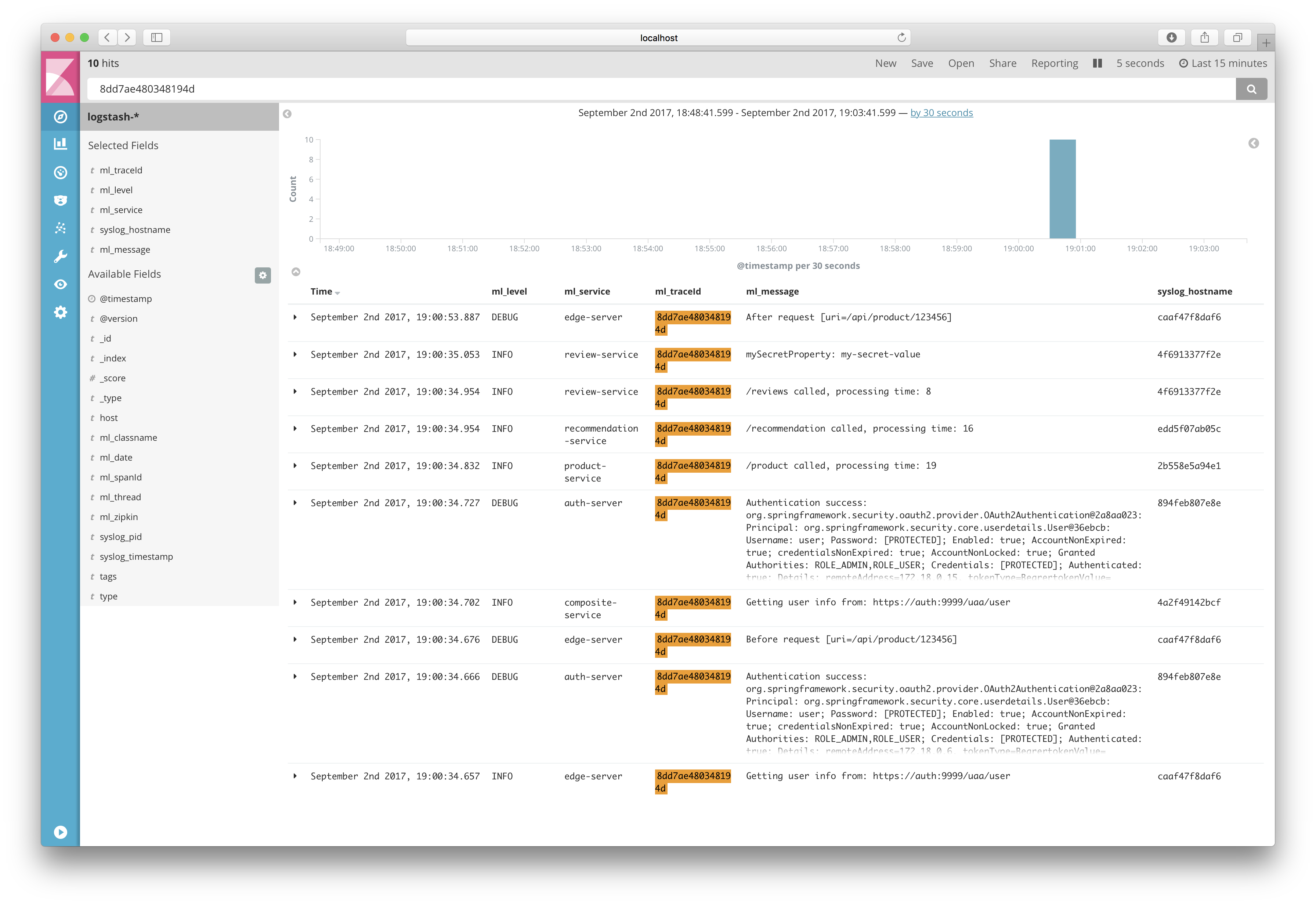
Voila, here are all the log events for the processing of the request!
Nice, isn’t it!
Note: If you wonder from where the very useful traceId’s came, you can take a look into the previous blog post blog post #7 about spring-cloud-sleuth!
Remove the search criteria (the trace id) from the search dialog in Kibana.
Next, scale the Recommendation Service to two instances:
$ docker-compose scale rec=2
After a while you should see a log event in Kibana from the recommendation-service with a message like:
Started RecommendationServiceApplication in 13.863 seconds (JVM running for 14.756)
Now, filter log events in Kibana so that you only will see log events from the Recommendation Service. Click on the “ml_service” field in the list of selected fields to the left, then click on the magnifying glass with a “+” - sign after the recommendation-service.
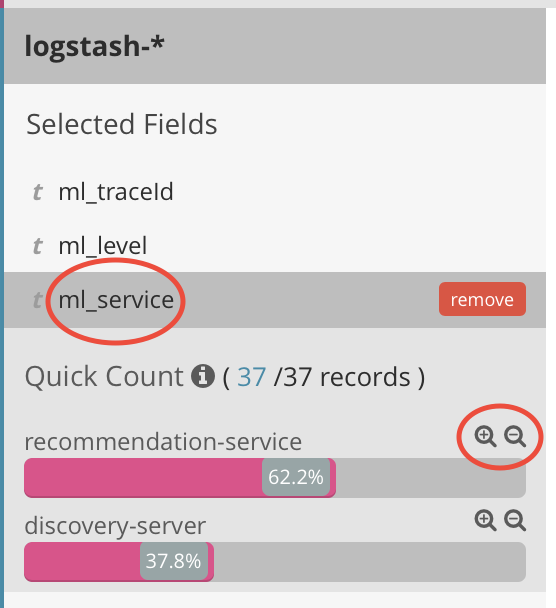
A filter for the recommendation service is now displayed under the search field:
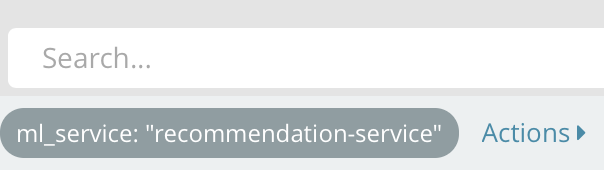
Now, only events from the “recommendation-service” should be visible!
Make a few new calls and see how the value of the “syslog_hostname” varies as requests are load balanced over the two instances:

There is much more to say about the ELK stack but this is as far we get in this blog post. We have, at least, seen how to get started using the ELK stack in a containerized world :-)
Now we have seen how we can use the ELK stack to capture, search and visualize log events. In the previous blog post we saw how we could use Zipkin together with Spring Cloud Sleuth to understand the response times in a request that is processed by multiple microservices. One piece of important information is still missing though, i.e. how much hardware resources are utilized by our microservices on an individual level. For example, how much CPU, memory, disk and network capacity is each microservice instance consuming?
This is a question that I will try to answer in the next blog post in the blog series - Building Microservices, where we will meet Prometheus with friends, stay tuned :-)