Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

How do you approach using Kafka to store your data when building a HTTP api? In this series we build an application which would traditionally be backed by a classic database, the basic ‘Create-Read-Update-Delete’ api. Instead of a traditional database we store our data in Kafka and over the series look at some of the issues with this approach and how you can solve them. If you want to read from the beginning, you can find Part 1 here.
In Part 2 we added the ability to produce user records to Kafka. This allows creating, updating and deleting users. In this post we look at scaling our application by running multiple instances of it. As it is we could just run several instances of the application in parallel to handle more traffic, but it would mean all instances consume all user records from the user topic. That also means we have to keep all users in our state map in every instance, we can do better than that!
Kafka scales by dividing topics into partitions, generally all records with a given key always end up on the same partition. In other words; records are partitioned by their key. Partitions can then be spread out among the brokers to reduce the load on each broker.
Since Kafka guarantees the ordering of records within a single partition (but not across several partitions) we can rely on the latest record with a given key always being the most up to date. One thing to keep in mind is that the partitioning is done client-side, i.e. the producer picks which partition to produce the record to. In general this is handled by the Kafka client library you use, and for the most part they use the same algorithm.
Let’s look at our user topic, here I use a tool called kafkacat to consume the records on a topic.
$ kcat -b localhost:50278 -t user -o 0 -f 'partition=%p k=%k %s\n'
partition=0 k=bob_smith@example.com {"name":"Bob Smith","email":"bob_smith@example.com"}
partition=0 k=sarah_black@example.com {"name":"Sarah Black","email":"sarah_black@example.com"}
partition=0 k=bob_smith@example.com {"name":"Bob Davis","email":"bob_smith@example.com"}
partition=0 k=bob_smith@example.com
partition=4 k=emma_turner@example.com {"name":"Emma Turner","email":"emma_turner@example.com"}
partition=6 k=helen_garcia@example.com {"name":"Helen Garcia","email":"helen_garcia@example.com"}
As you can see all three records with key bob_smith@example.com are all on partition 0.
So how can we use this to spread the users over our application instances and reduce the load on each instance?
The concept of consumer groups is a commonly used concept when building Kafka applications. It allows multiple consumers cooperating to consume data from a topic. The partitions of the topic are split up among the consumers, as consumers come and go the partitions are re-assigned. This assignment of partitions is called rebalancing. We will look closer at rebalancing later, but first we are going to add our application to a consumer group.
flag.StringVar(&group, "g", "go-kafka-state", "The Kafka ConsumerGroup")
cl, err := kgo.NewClient(
...
kgo.ConsumerGroup(group),
...
)
Easy enough! Running your application now should yield the same results as before. However, if you restart the application you will notice that no records are consumed the second time. When records are consumed by a member of a consumer group the consumer commits the offset of a consumed record to an internal Kafka topic. These offsets are committed per topic and partition for the group. If the consumer for some reason should leave the consumer group another consumer in the group is assigned those partitions and can start consuming where the first consumer stopped.
This is very handy in many cases where you do not want to re-process records. Since we store the current state of our data on our Kafka topic however we want our application to consume from the beginning of the partitions it is assigned during a rebalance so that the full state can be consumed into our user map. Luckily franz-go allows us to hook into the process and adjust the offsets for the assigned partitions, after the offsets have been fetched but before the application starts consuming.
cl, err := kgo.NewClient(
...
kgo.AdjustFetchOffsetsFn(func(ctx context.Context, m map[string]map[int32]kgo.Offset) (map[string]map[int32]kgo.Offset, error) {
for k, v := range m {
for i := range v {
m[k][i] = kgo.NewOffset().At(-2).WithEpoch(-1)
}
}
return m, nil
}),
...
)
We’re not going to dive to deeply into the specifics here, more information can be found in the godoc of franz-go. This results in the whole topic being read in each time the group is rebalanced, this could take a while if we have a lot of users, not great in the long run. But for now it is an easy shortcut to allow us to ensure we have the correct state in our map.
Before we move on I will mention a few different things could be done to improve this. For example we do not need to reconsume messages on partitions we already owned before the rebalance. Keeping track of which partitions and offsets we have in our local state and adjusting the offset accordingly after a rebalance would be a fairly easy improvement to make. We could also use a memory-mapped DB such as BoltDB or Badger to avoid keeping everything in memory. This would also allow you to optimize further by not re-consuming the full history in-case the state already exists on disk on startup, consuming only from the last record seen in the local state. Kafka Streams (the Java library) does it this way for example. But we are sticking to the more naive approach and moving on!
Right now we are only running a single instance of our application, so the consumer group only has a single member. That means the single instance will consume all partitions and the whole state. If we were to run a second instance of the application the group would have two members, and the partitions would be split evenly across the two instances. That means half the state is available on the first instance, and the other half is available on the second instance. This is a problem for our HTTP api since we do not know which instance holds which half of the users.
Let us look at what happens when we run our application in two instances. We have already prepared the application to configure the HTTP addr with parameter, using that parameter we can start a second instance on a separate port, say 8081.
$ go run . -l :8081
When you start the second instance you see that each record is consumed by one of the instances, which one depends on which partition the specific instance was assigned during the rebalance. If you try to fetch a user from each instance respectively you notice that one of the instances responds with a 404.
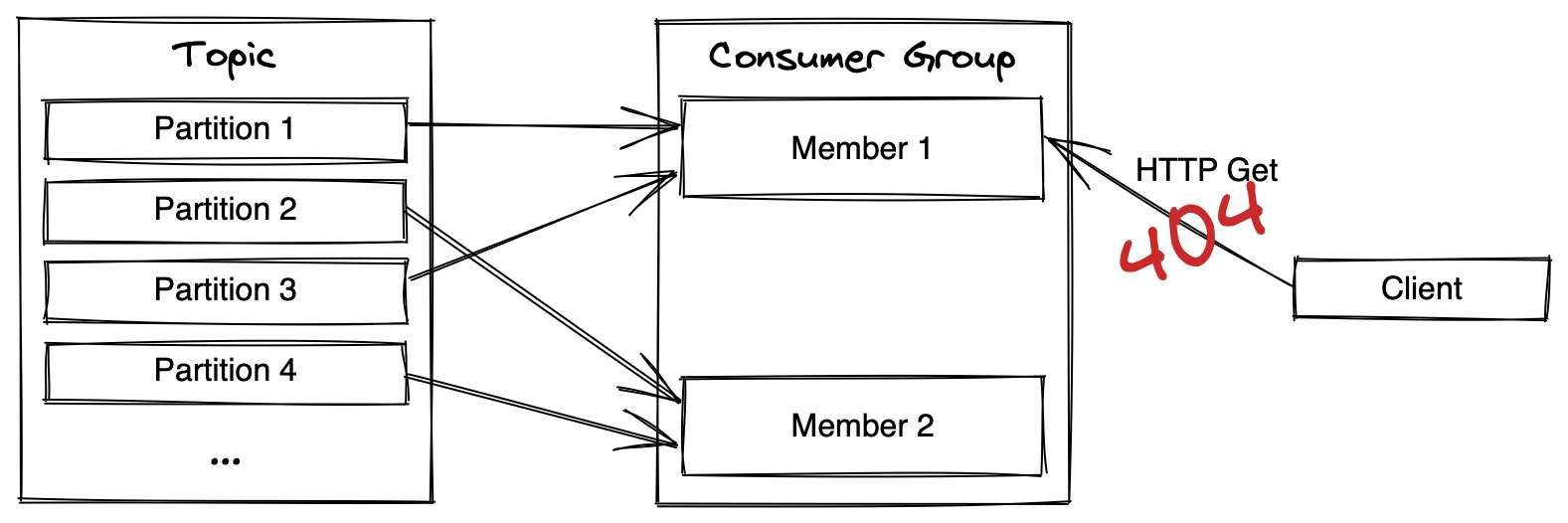 The diagram above illustrates this problem. Try it out, by requesting a user from the ‘wrong’ instance you end up with a 404 response!
The diagram above illustrates this problem. Try it out, by requesting a user from the ‘wrong’ instance you end up with a 404 response!
We have introduced the concept of consumer groups and the core building block of Kafka, partitions. We have also started running our application in multiple instances, doing so introduces a problem with distributed state which is what we will look into in the next part!
Full source is available at github.