Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

The journey of optimizing a Go web service.
Recently, I stumbled upon an interesting article on Medium by Dmytro Misik, having one of those hard-to-resist titles with “Go vs Rust” and “performance” in it.
Of course, I couldn’t resist clicking, and I was quite pleasantly surprised by a well written article. The bottom line was - that for the scenario in the article, the Rust solution provided roughly twice the throughput regarding requests per second.
While the subject was “Web service performance”, the work done for each web service invocation was to perform so-called “text similarity” processing, which includes:
A lot of the work done for each request - in my humble opinion - is not “web service” related (e.g. things not related to HTTP/TCP/routing/multiplexing/networking etc.) - the task does test a variety of aspects such as JSON, regexp, data structures and maths, making it a quite good case of comparing implementation efficiency across various domains within the service.
I couldn’t resist a good optimization challenge (one issued by myself!). Continue reading to see if I were able to close the performance gap, making the Go solution perform more like the Rust one.
I forked the original repository and started by building both solutions:
Rust:
rustc --version
rustc 1.83.0 (90b35a623 2024-11-26) (Homebrew)
cargo build --release
...
Finished `release` profile [optimized] target(s) in 44.38s
Go:
go version go1.23.4 darwin/amd64`
time go build -o bin/app main.go
go build -o bin/app main.go 1,07s user 0,86s system 295% cpu 0,653 total
While we are not benchmarking compile/build times, I never cease to be amazed at how fast Go compiles stuff.
The repository comes with a K6 test script that calls the POST /similarity API with two 10000-character texts to be compared, cycled from a .csv file with 1000 texts.
The original post on Medium uses an 8-minute load test with ramp-up and ramp-down. In order to save myself some time benchmarking, I adjusted the load profile to scale faster up to 800 virtual users (VUs) and then down again over a total of 2 minutes and 30 seconds.
On my MacBook Pro 2019 equipped with a Intel(R) Core(TM) i9-9880H CPU @ 2.30GHz CPU, the baseline performance was as follows:
Rust
checks.........................: 100.00% 1513464 out of 1513464
data_received..................: 126 MB 837 kB/s
data_sent......................: 15 GB 102 MB/s
http_req_blocked...............: avg=4.52µs min=1µs med=4µs max=26.76ms p(90)=5µs p(95)=5µs
http_req_connecting............: avg=318ns min=0s med=0s max=26.55ms p(90)=0s p(95)=0s
✓ http_req_duration..............: avg=74.45ms min=810µs med=62.81ms max=314.23ms p(90)=146.01ms p(95)=199ms
{ expected_response:true }...: avg=74.45ms min=810µs med=62.81ms max=314.23ms p(90)=146.01ms p(95)=199ms
✓ http_req_failed................: 0.00% 0 out of 756732
http_req_receiving.............: avg=41.23µs min=12µs med=29µs max=49.33ms p(90)=36µs p(95)=46µs
http_req_sending...............: avg=51.42µs min=20µs med=43µs max=166.95ms p(90)=56µs p(95)=78µs
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=74.35ms min=0s med=62.72ms max=314.16ms p(90)=145.92ms p(95)=198.87ms
http_reqs......................: 756732 5044.762625/s
iteration_duration.............: avg=75.37ms min=1.21ms med=63.75ms max=315.08ms p(90)=146.94ms p(95)=199.97ms
iterations.....................: 756732 5044.762625/s
vus............................: 1 min=1 max=799
vus_max........................: 800 min=800 max=800
Go
checks.........................: 100.00% 679712 out of 679712
data_received..................: 56 MB 376 kB/s
data_sent......................: 6.9 GB 46 MB/s
http_req_blocked...............: avg=4.88µs min=1µs med=4µs max=21.38ms p(90)=5µs p(95)=5µs
http_req_connecting............: avg=805ns min=0s med=0s max=5.57ms p(90)=0s p(95)=0s
✓ http_req_duration..............: avg=167.93ms min=1.84ms med=15.12ms max=6.28s p(90)=635.71ms p(95)=985.33ms
{ expected_response:true }...: avg=167.93ms min=1.84ms med=15.12ms max=6.28s p(90)=635.71ms p(95)=985.33ms
✓ http_req_failed................: 0.00% 0 out of 339856
http_req_receiving.............: avg=37.03µs min=12µs med=29µs max=27.9ms p(90)=37µs p(95)=42µs
http_req_sending...............: avg=53.36µs min=20µs med=42µs max=16.81ms p(90)=56µs p(95)=78µs
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=167.84ms min=0s med=15.03ms max=6.28s p(90)=635.64ms p(95)=985.24ms
http_reqs......................: 339856 2265.632339/s
iteration_duration.............: avg=168.74ms min=2.28ms med=15.93ms max=6.28s p(90)=636.46ms p(95)=986.2ms
iterations.....................: 339856 2265.632339/s
vus............................: 1 min=1 max=799
vus_max........................: 800 min=800 max=800
There’s are lot of numbers in the output from K6, I will primarily focus on requests/s and averages (avg). In both figures, Rust is way faster, even more so than in the original article on Medium:
Rust: 5045 req/s, avg 74 ms.
Go: 2266 req/s, avg: 168 ms.
Approx 2.2x in favour of Rust! Also note that the Go solution offers much worse max and P(95) values, possibly due to GC pauses?
So, in order to determine if there are any possible optimizations, one should consider (at least) two things:
This one is relatively straightforward to examine. We already know that HTTP processing and routing, JSON, regexp, mapping and maths are key areas of this particular solution.
One of the most obvious things to look at first is the Bill-of-Materials, e.g. the go.mod file:
require (
github.com/gofiber/fiber/v2 v2.52.5
golang.org/x/exp v0.0.0-20241108190413-2d47ceb2692f
)
Just two direct dependencies, where gofiber is an HTTP router/muxer built on top of fasthttp, a combination that is often regarded as one of the most (if not the most) performant HTTP/router stacks in the Go ecosystem.
However, this also means there are no custom map implementations, regexps or JSON marshalling/unmarshalling etc. in use, so perhaps there’s room for faster options?
I just love the built-in profiling tools of Go. Just add an import and 3 lines of code to your main.go and you’re reading for profiling:
import _ "net/http/pprof"
func main() {
go func() {
log.Println(http.ListenAndServe(":6060", nil))
}()
}
By recompiling and then starting the program and K6 script again, we can use (for example) curl to capture a 30-second CPU profile and save it to disk:
curl http://localhost:6060/debug/pprof/profile\?seconds\=30 --output profile1.pprof
(or we can go to interactive console directly using go tool pprof http://localhost:6060/debug/pprof/profile\?seconds\=30)
Once finished, use go tool pprof <filename> to enter the interactive console:
$ go tool pprof profile1.pprof`
File: main
Type: cpu
Time: Jan 3, 2025 at 10:06pm (CET)
Duration: 30.10s, Total samples = 233.59s (750.99%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
There’s a ton of things one can do. A good first candidate is to generate a graph visualization in your standard web browser:
(pprof) web
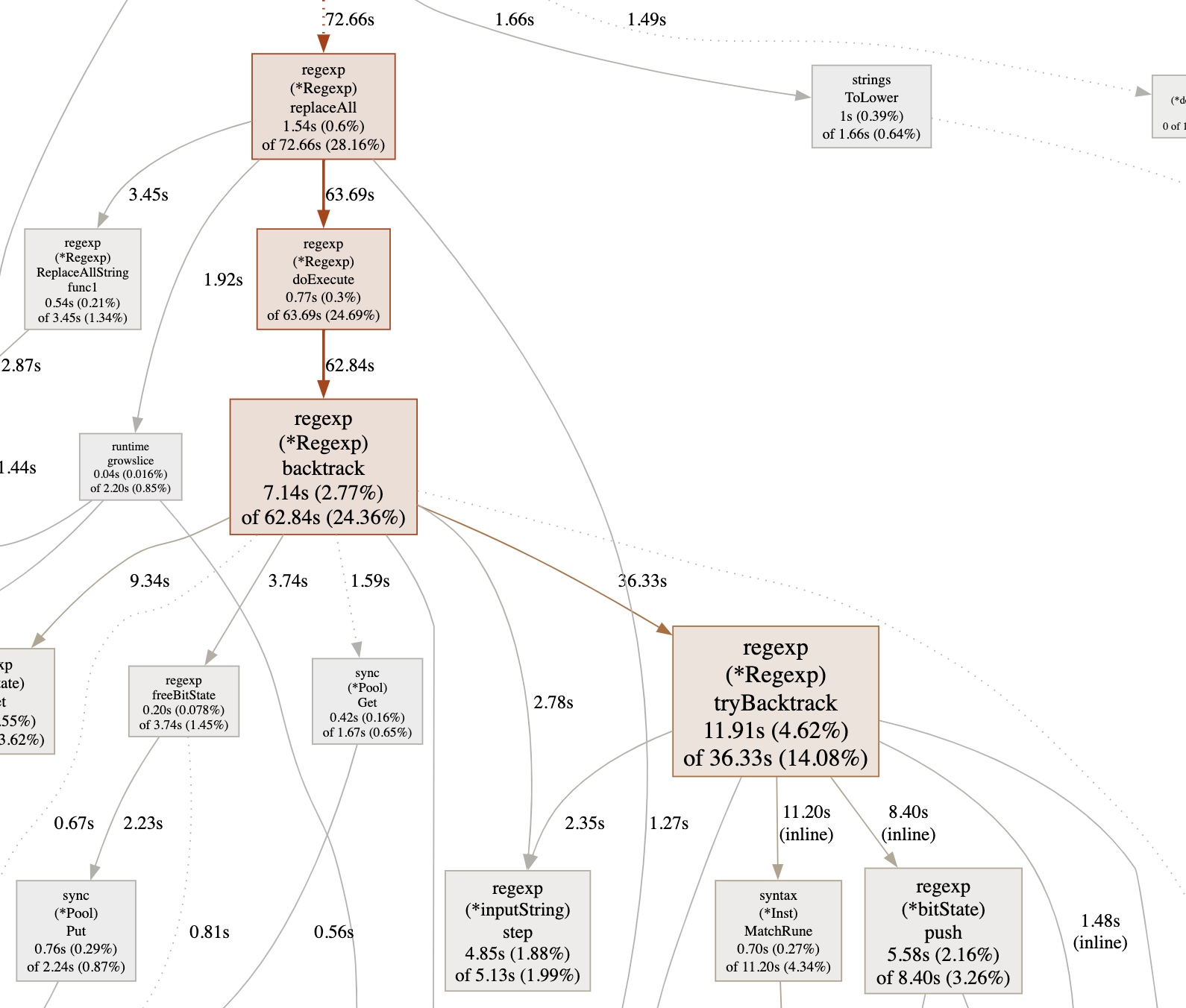
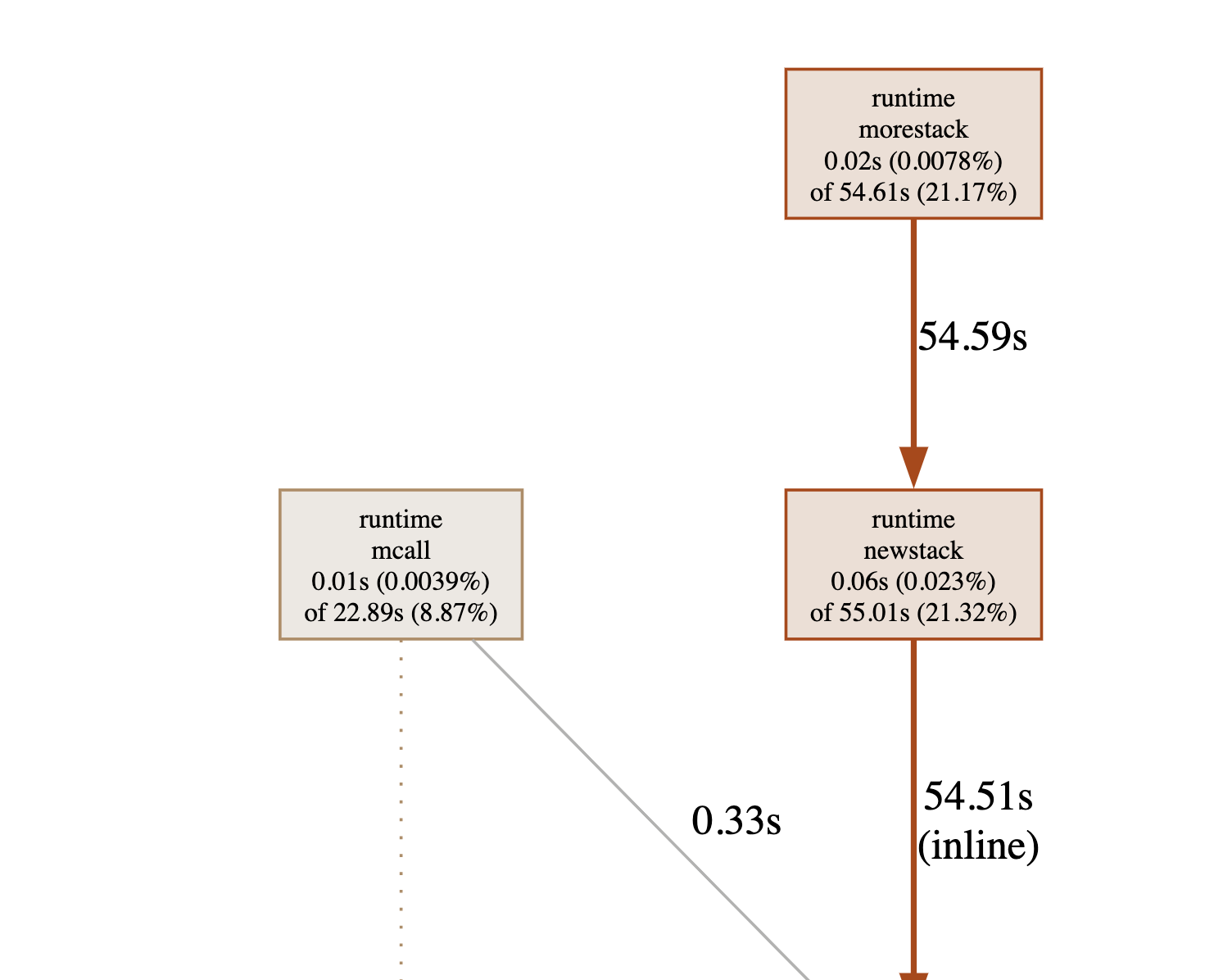
Since the graph is quite large, I copied two interesting parts of it - the first clearly indicating the regexp package as being quite busy, the other the runtime package and calls to morestack.
Personally, I prefer to go into even more detail using (pprof) weblist which generates a listing of time spent for each line of code, generated by weblist <regexp for what files to view> which then opens in your web browser:
(pprof) weblist main.go
A listing of main.go with flat and cumulative time spent on each line will open. Let’s focus on the start of similarityHandler which is the function invoked by fiber for each incoming HTTP request.
Total: 240ms 120.13s (flat, cum) 41.34%
42 . . func similarityHandler(c *fiber.Ctx) error {
43 . 130ms var req SimilarityRequest
44 . 3.87s if err := c.BodyParser(&req); err != nil {
45 . . return c.Status(fiber.StatusBadRequest).JSON(fiber.Map{
46 . . "error": "Bad Request",
47 . . })
48 . . }
49 . .
50 . 41.52s text1 := normalizeText(req.Text1)
51 . 50.77s text2 := normalizeText(req.Text2)
... rest omitted for now ...
We see that total time spent in this function (and functions called by it) is 120.13 seconds. The first lines are JSON-parsing of the incoming payload (done using encoding/json from the stdlib). However, the next two lines are mildly shocking to be honest, using approx. 92 of 120 seconds cumulatively. What on earth is normalizeText doing?
Not that much, in all honesty. Each invocation is taking a 10000 character string and removing punctuations and replacing non ` ` whitespaces (such as tabs) with ordinary whitespaces.
Total: 10ms 92.29s (flat, cum) 31.76%
101 . . func normalizeText(text string) string {
102 . 1.97s lower := strings.ToLower(text)
103 . 29.70s noPunctuation := punctuationRegex.ReplaceAllString(lower, "")
104 10ms 60.62s cleanText := whitespaceRegex.ReplaceAllString(noPunctuation, " ")
105 . .
106 . . return strings.Trim(cleanText, " ")
107 . . }
Some ordinary use of the strings package and then regexp-based replacing. That’s a remarkable amount of time, more than 3/4th of the total time spent in the HTTP request handler is spent on sanitizing the input text, making it ready for similarity checking. Can we do something about this?
Let’s start by cheating. The input text from the .csv isn’t very realistic as it only contains . as punctuation marks, and no other whitespaces than ` . Let's use a few simple calls to strings.ReplaceAll` instead:
func normalizeTextCheat(text string) string {
noPunctuation := strings.ReplaceAll(strings.ToLower(text), ".", "")
cleanText := strings.ReplaceAll(noPunctuation, "\t", " ")
return strings.Trim(cleanText, " ")
}
For this particular input the code above produces correct output, and provides a significant speedup. For our 2m30 second benchmark:
checks.........................: 100.00% 1346440 out of 1346440
✓ http_req_duration..............: avg=84.04ms min=702µs med=7.74ms max=3.97s p(90)=295.04ms p(95)=540.62ms
iterations.....................: 673220 4488.03325/s
4488 req/s is almost double the throughput, and average latency is more or less halved, going to 84 ms from 167 ms. While still more than 500 req/s short of the Rust solution, it’s much closer now - just by not using Go’s regexp package for text sanitizing. As it turns out - Go’s regexp engine is known for being notoriously slow. While the results on benchmarkgame tests doesn’t say everything about neither a particular language nor test, it is evident that the ~25-second completion time of Go stdlib regexp in the regex-redux test compared to the ~1-second completion time of Rust, may give us a hint that (a) Go regexp IS slow, and (b) using (native Go) regexp for text sanitation isn’t really feasible in hot code paths such as this “similarityHandler”.
Yes, I know - the strings.ReplaceAll calls are NOT doing the same thing as the regular expressions were. Let’s look more closely at how to address this particular bottleneck.
Some alternative regexp implementations should be possible to use, such as:
I decided to use go test -bench to benchmark various implementations of sanitizeText. Let’s start with the original stdlib regexp + the “cheating” strings.ReplaceAll solutions.
All benchmarks are written like this, running normalize twice per iteration with different inputs:
func BenchmarkOriginalRegexp(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = normalizeText(line1) // <-- each different benchmark just uses another implementation here
_ = normalizeText(line2) // <-- each different benchmark just uses another implementation here
}
}
Initial results:
BenchmarkOriginalRegexp-16 876 1291924 ns/op
BenchmarkCheat-16 28342 43020 ns/op
At least in this micro-benchmark, the cheat variant is unsurprisingly much faster - throughput is more than 30x - but is also very limited feature-wise.
Looking at the benchmark game regex-redux test again, we do see Go entries performing much better than the stdlib option. Using https://github.com/GRbit/go-pcre which is a Go wrapper around libpcre, the best Go result is just over 3 seconds. While still ~3x slower than the Rust performance, it’s possible it could provide a nice speedup compared to the stdlib regexp package.
I installed go-prce on my Mac, including brew install pcre. While I could compile the application with something like:
var whitespaceRegexPcre = pcre.MustCompileJIT("\\s+", 0, pcre.STUDY_JIT_COMPILE)
func normalizeTextGoPCRE(text string) string {
text = strings.ToLower(text)
text = whitespaceRegexPcre.ReplaceAllString(text, " ", 0)
// ... same for punctuation and then trim and return ...
}
Running even a simple unit test with go-prce either froze my computer consuming 100% CPU, or did not perform any replacements at all. It’s probably due to me misunderstanding how to construct a valid PCRE regexp, though I did fiddle around with some online PCRE regexp web pages where my simple expressions seemed to select punctuations or whitespaces just fine. I simply ran out of patience and decided go-pcre wasn’t worth the hassle.
There also exists a transpiled version of PCRE2, go.arsenm.dev/pcre. I.e - the original C source code has been auto-translated into Go and then wrapped for an easy-to-use API.
import "go.arsenm.dev/pcre"
var whitespacePcre2 = pcre2.MustCompile("\\s+")
var punctuationPcre2 = pcre2.MustCompile("[^\\w\\s]")
func normalizeTextPCRE2(text string) string {
lower := strings.ToLower(text)
noPunctuation := punctuationPcre2.ReplaceAllString(lower, "")
// ... clean whitespace with PCRE2 and return ...
}
The API seems to be drop-in compatible with the standard library. Read on for benchmarks…
Another option was to utilize a CGO wrapper around the C++ re2 which works as a drop-in replacement for the standard library regexp package. It can execute both using Webassembly on Wazero (an Go embeddable WASM runtime) or using CGO.
However, go-re2 states in their README that Note that if your regular expressions or input are small, this library is slower than the standard library., so not guaranteed to provide a speed-up for this particular use-case.
The code is very simple:
import "github.com/wasilibs/go-re2"
var punctuationRegexRE2 re2.MustCompile(`[^\w\s]`)
func normalizeTextRE2(text string) string {
lower := strings.ToLower(text)
noPunctuation := punctuationRegexRE2.ReplaceAllString(lower, "")
// ... clean whitespace with RE2 and return omitted for brevity ...
}
By default, go-re2 uses the Webassembly runtime. To use CGO instead, I added //go:build re2_cgo to my main.go.
BenchmarkOriginalRegexp-16 876 1291924 ns/op
BenchmarkCheat-16 28342 43020 ns/op
BenchmarkGoRE2_WASM-16 457 2564612 ns/op
BenchmarkGoRE2_CGO-16 722 1580190 ns/op
BenchmarkGoPCRE2-16 332 3555101 ns/op
Quite depressing. For this use-case the standard library is actually much faster than the alternatives. For RE2, the CGO version was about 57% faster than the WASM one. Both were significantly slower than Go stdlib and 50-60x slower than the “cheat”. The transpiled PCRE2 was even slower, reaching about a third of the Go stdlib performance.
Unless go-pcre - which I couldn’t get to work - is significantly faster, I suspect the regular expression route for simple text sanitizing of a 10 kb input, is a quite bad use-case for Go. Remember - the Rust result in the benchmarkgames regex-redux test was more than 20x faster than Go stdlib…
While the headline of this section sounds like an 80’s metal album, I decided to see if I could write something faster by hand based on the “cheat” solution, but without actually cheating.
By not cheating, I mean supporting all US-ASCII punctuation and whitespace characters. I did however decide to NOT support Unicode code points or any extended ASCII using > 1 byte per character.
ASCII contains about 28 punctuation characters and 7 whitespace characters.
A really naive but nevertheless fun approach is to create a nested loop, iterating over each possible punctuation and whitespace, for each character in the input. Remember, we want to remove all punctuations and replace any non-space whitespaces with a single space. It looks something like this:
var punctuations = []byte{'[', '!', '"', '#', '$', '%', '&', '\'', '(', ')', // rest omitted for brevity
func normalizeTextNestedForLoops(text string) string {
out := make([]byte, len(text)) // prepare output having sufficient capacity
j := 0
OUTER:
for i := 0; i < len(text); i++ {
for _, c := range punctuations {
if c == text[i] {
continue OUTER // Was a punctuation, we can skip
}
}
out[j] = text[i]
// Remove tabs etc by comparing the ASCII-code against the "whitespace" codes.
if text[i] > 7 && text[i] < 14 {
out[j] = ' '
}
j++ // increment output buffer index
}
// since we did not add punctuations, we need to trim the extra allocated space not written to at the end.
return strings.TrimSpace(string(out[0:j]))
}
This approach (BenchmarkReplaceNestedForLoops in the listing below) produces the expected result. Is it fast? Yes, while pretty dumb - it is about 3x times faster than using Go regexp.
BenchmarkOriginalRegexp-16 876 1291924 ns/op
BenchmarkCheat-16 28342 43020 ns/op
BenchmarkReplaceNestedForLoops-16 2476 413784 ns/op
However, it’s also more than 10x slower than the “cheat” version. Not surprising - after all - the new implementation supports 28 punctuation marks and 6 whitespaces instead of one of each type.
However - we can do better.
The above solution can be both simplified and made much faster by utilizing the fact that ASCII groups the same types of characters into chunks.
Whitespaces: Decimal 8-13
Punctuations: Decimal 33-47, 58-64, 91-96, 123-126
We can remove the slice with '[', '!', '"', '#', '$', ... and instead compare each input character against these ranges:
func normalizeTextUsingAsciiRanges(txt string) string {
text := []byte(txt)
out := make([]byte, len(text))
j := 0
for i := 0; i < len(text); i++ {
if text[i] > 32 && text[i] < 48 || text[i] > 57 && text[i] < 65 || text[i] > 90 && text[i] < 97 || text[i] > 122 && text[i] < 128 {
continue // Skip.
}
// ... rest omitted ...
Also, we can slightly speed up strings.ToLower (which has a lot of code to handle non-ASCII) by identifying the [A-Z] range and adding decimal 32 to convert them into lower-case:
// Check for upper-case by checking 65->90 range. lower-case [a-z] is exactly offset by +32.
if text[i] > 64 && text[i] < 91 {
out[j] = text[i] + 32
} else {
out[j] = text[i]
}
Faster? Read on and find out!
Given that our sanitation objective is to just have words + spaces left, I realized that fewer comparisons needs to be performed if we “invert” so only SPACE + [a-zA-Z] is added to the output:
func normalizeTextUsingAsciiRangesInverted(txt string) string {
text := []byte(txt)
out := make([]byte, len(text))
j := 0
for i := 0; i < len(text); i++ {
// If a-zA-Z or space
if text[i] == 32 || (text[i] > 64 && text[i] < 91) || (text[i] > 96 && text[i] < 123) {
// Add to output after possibly converting to lower-case, whitespace handling etc...
} else if text[i] < 14 && text[i] > 7 {
// Replace tabs etc with SPACE.
}
// ... rest omitted ...
This is probably a bit faster.
As most seasoned Go developers know, var b = []byte("some string") and var s = string(aByteSlice) works fine in most use cases, but they do result in memory allocations.
By changing normalizeTextUsingAsciiRangesInverted to instead accept and return []byte, some unnecessary allocations are avoided.
func normalizeTextUsingInvertedAsciiRangesBytes(text []byte) []byte {
out := make([]byte, len(text))
j := 0
for i := 0; i < len(text); i++ {
// If a-zA-Z or space
if text[i] == 32 || (text[i] > 64 && text[i] < 91) || (text[i] > 96 && text[i] < 123) {
// ... rest omitted ....
return bytes.TrimSpace(out[0:j]) // use bytes.TrimSpace instead
}
Turns out there is a built-in option for efficient string-replacing in the standard library: strings.Replacer. It works by first building a “replacer” instance from a set of find->replace pairs, and then using that replacer instance by feeding it the string to search and replace in:
var replacementPairs = []string{
"!", "",
".", "",
"#", "",
"$", "",
"\t", " ",
"\n", " "}
var replacer = strings.NewReplacer(replacementPairs) // Note - just initialized once!
func normalizeTextWithReplacer(text string) string {
text = strings.ToLower(text)
text = replacer.Replace(text)
return strings.Trim(text), " ")
}
As it turns out, strings.Replacer is very efficient and uses some quite clever tricks such as setting up an array from 0-255 where each index corresponds to an ASCII code, where the value at each index is a byte-slice representing what to replace that particular index with, or if nil, keep as-is. It also performs some pre-analysis of input data to pick the most efficient algorithm, where the analysis even uses some hand-written platform-specific (e.g. amd64, arm64 etc.) assembly code to utilize specific CPU instructions for efficiency.
Inspired by strings.Replacer, I decided to derive my own replacer, working directly with []byte and limiting it to 7-bit ASCII and 0..1 replacement bytes.
The basics are the same as strings.Replacer; a [256]byte array where each index maps directly to its ASCII decimal value. I.e. - if I want to replace . with ` , I'd pass a "pair" using a []string{“.”, “ “}`:
Internally, the constructor function will handle the conversion from single-character string elements to byte. The full implementation with some extra comments:
type byteReplacer struct {
replacements [256]byte
}
func newByteReplacerFromStringPairs(pairs []string) *byteReplacer {
r := [256]byte{} // Array is used as a lookup table where index == ascii decimal value to replace byte for. If not set (NULL), do not replace.
for i := 0; i < len(pairs); i += 2 {
key := pairs[i]
if len(pairs[i+1]) > 0 {
r[key[0]] = pairs[i+1][0] // Only use first byte of replacement string.
} else {
r[key[0]] = 8 // Use BACKSPACE ascii char to denote deletion.
}
}
return &byteReplacer{replacements: r}
}
func (r *byteReplacer) Replace(data []byte) []byte {
out := make([]byte, len(data)) // Allocate at least as many bytes as the input, important for performance.
j := 0 // Output index.
for _, b := range data {
if r.replacements[b] != 0 { // Check if the lookup table (array) contains a replacement entry.
if r.replacements[b] != 8 { // If not our special BACKSPACE signaling delete, add with replacement.
out[j] = r.replacements[b]
j++
}
} else {
// No mapping, just write byte to output as is.
out[j] = b
j++
}
}
return out[0:j] // Return out, slicing off any allocated but unused slice memory.
}
A neat little trick to avoid an extra pass over the input texts to enforce lower-case, is to include pairs to convert all upper-case to lower-case as replacements:
var myByteReplacer = newByteReplacerFromStringPairs([]string{"A","a", "B", "b", ... and so on ...})
Using this little byteReplacer in the hot-path of the similarityHandler works fine and hopefully provides a nice performance boost.
I thought the byteReplacer was kind of neat, so I put it in a repo of its own so it can be used as a Go module.
Time for results for our various optimization strategies for input text sanitation!
Here’s the full listing, including both regexp and brute-force approaches. The first figure is number of completed invocations during the benchmark run, i.e. “higher is better”, while “lower is better” applies to ns/op.
BenchmarkOriginalRegexp-16 876 1291924 ns/op
BenchmarkCheat-16 28342 43020 ns/op
BenchmarkGoRE2_WASM-16 386 2700073 ns/op
BenchmarkGoRE2_CGO-16 722 1580190 ns/op
BenchmarkGoPCRE2-16 332 3555101 ns/op
BenchmarkReplaceNestedForLoops-16 2476 413784 ns/op
BenchmarkReplaceUsingAsciiRanges-16 16790 73910 ns/op
BenchmarkReplaceUsingInvertedAsciiRanges-16 19258 62578 ns/op
BenchmarkReplaceUsingInvertedAsciiRangesBytes-16 22662 53272 ns/op
BenchmarkStringsReplacer-16 27194 44348 ns/op
BenchmarkByteReplacer-16 58910 20157 ns/op
First off - the alternate regular expression solutions performs miserably for this use-case - 2.5-3x worse than the (already quite slow) Go stdlib regexp package. The “cheat” solution that was tailored to the benchmark’s CSV input data performed at least 30x times better than regexp, but it was - as already stated - just a little hack.
Moving on to the various replacement strategies - the brute-force nested for-loop outperforms regexp by 2.8x, but is still vastly inferior to the more efficient ASCII-range based approaches, where the “inverted” one matching desired characters directly on []byte approaches “cheat” performance levels.
Nevertheless, using the stdlib strings.Replacer approach is definitely the best solution this far - being available out-of-the-box in the stdlib (and it has multi-byte/UTF-8 support), outperforming all options except the “cheat” one.
Still - if you can live with strict 7-bit ASCII support and only single-byte replacements, my derivative byteReplacer is performance-wise about 2.4x faster than strings.Replacer and a whopping 67x times faster than the original regexp solution!
If we apply the byteReplacer version of the sanitation code on the overall Web Service benchmark, i.e. the only change is that the calls to normalizeText(text1) are replaced by:
text1 := byteReplacer.Replace([]byte(req.Text1))
text2 := byteReplacer.Replace([]byte(req.Text2))
The result of the 2m30s benchmark run is:
checks.........................: 100.00% 1354268 out of 1354268
✓ http_req_duration..............: avg=83.53ms min=658µs med=8.11ms max=4.26s p(90)=294.58ms p(95)=543.75ms
iterations.....................: 677134 4512.488576/s
We’ve more than doubled the performance of the original Go implementation!
A new 30-second pprof profile run provides new insights:
Total: 250ms 43.13s (flat, cum) 18.68%
54 . . func similarityHandler(c *fiber.Ctx) error {
55 . 190ms var req SimilarityRequest
56 . 7.59s if err := c.BodyParser(&req); err != nil {
57 . . return c.Status(fiber.StatusBadRequest).JSON(fiber.Map{
58 . . "error": "Bad Request",
59 . . })
60 . . }
61 . .
62 . . text1 := byteReplacer.Replace([]byte(req.Text1))
63 10ms 10ms text2 := byteReplacer.Replace([]byte(req.Text2))
64 . .
65 . 150ms words1 := strings.Split(string(text1), " ")
66 . 100ms words2 := strings.Split(string(text2), " ")
... rest omitted ...
As seen above, the profiling now reports that only 43 out of a total of 230 seconds are spent in the similarityHandler, and that the text sanitation happening on lines 62-63 now is basically negligible, though this may be an effect of how the frequency the Go profiler collects measurements.
Instead, a good fraction of total time is now spent on JSON unmarshalling and on code further down (omitted above) related to counting words and the text-similarity computations. Totally, a pprof top listing shows that overall, most time is spent on syscall:
84.56s 36.63% 36.63% 84.68s 36.68% syscall.syscall
This code is called by fasthttp and net.Conn.Read, probably doing some syscall to the underlying OS to read/write data for the incoming requests.
To summary, the table below shows us results for the default Rust implementation and some Go variants, where I also added a run using strings.Replacer:
Go regexp : 2266 req/s, avg: 168 ms.
Go strings.Replacer : 4296 req/s, avg. 87.2 ms.
Go cheat : 4488 req/s, avg: 84.0 ms.
Go byteReplacer : 4512 req/s, avg: 83.5 ms.
Rust : 5045 req/s, avg: 74 ms.
With the byteReplacer sanitation code, the Go solution is a hair faster than the performance of the “cheat” version that was tailored to the exact input by the benchmark .csv file. While still ~12% slower than the Rust counterpart, I think we’ve shown that using some simple hand-written Go code instead of the regexp package, we could get a huge performance boost through relatively small means. The strings.Replacer from the stdlib also performs really well, just a few 100 req/s slower than the byteReplacer. Even though the byteReplacer offered roughly twice the performance of strings.Replacer in the microbenchmark, its effect on performance as a whole isn’t nearly as large since the fraction of total time spent on text sanitation is so much lower now.
In the next part, we’ll look at a few more optimizations, primarily parsing input JSON more efficiently, using alternate map and set implementations to make the similarity algorithm faster and examining how the number of memory allocations may affect performance.
Also, thanks to Dmytro Misik for the original article that got me started, and for open-sourcing his source code, so I can share my endeavours!
Thanks for reading! // Erik Lupander