Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

Recently, a proposal for adding low-level SIMD support to Go was marked as “Likely Accept”. In this blog post, we do some early experiments with the simd package using gotip to access the work-in-progress implementation.
SIMD is short for “Single Instruction, Multiple Data” and has actually been around since 1958 and the TX-2 computer, but in practice became commonplace with Intel Pentium MMX processors in the late 90’s.
So, what does “Single Instruction, Multiple Data” actually provide programmers? “Multiple Data” typically means some kind of vector containing a number of values, where a single CPU instruction can compute something for all values in the vector in a single instruction.
In the pseudo-example below, a SIMD “vectorized ADD” instruction operates on two 4-element vectors, adding them together and placing the result in a new vector.
// ADD
[2,4,6,8]
[3,5,7,9] +
=
[5,9,13,17]
Using ordinary non-SIMD Go, this vector addition is typically performed using a for-loop, one element at a time:
func AddVecUint8(x []uint8, y []uint8, result []uint8) {
for i := range x {
result[i] = x[i] + y[i]
}
}
However, if we would like to accelerate this vector addition, we’d want to utilize SIMD instructions such as the AVX/AVX2 VPADD-family, so multiple data elements could be added by a single CPU instruction.
Using Go assembly, that would roughly correspond to the following Go assembly code, put into a .s file and accessed through a func SimdAddUint8(a []uint8, b []uint8, result []uint8) stub function:
MOVQ a_base+0(FP), AX // Loads pointer to []uint8{2,4,6,8} into AX register
MOVQ b_base+24(FP), CX // Loads pointer to []uint8{3,5,7,9} into CX register
MOVQ result_base+48(FP), DX // Loads pointer to empty []uint8 to store the final result in into DX register
VPXOR Y0, Y0, Y0 // XORing by oneself sets all elements in vector register YMM0 to zero.
VMOVDQU (AX), Y0 // Load data from address in AX into YMM0 register
VMOVDQU (CX), Y1 // Load data from address in CX into YMM1 register
VPADDQ Y0, Y1, Y0 // Element-wise add of YMM0 and YMM1 registers, result is stored in YMM0 (overwrites)
VMOVDQU Y0, (DX) // Store contents (result) in YMM0 to memory address in DX
RET
The assembly above was generated using avo, which is a Go assembly code generator that generates assembly code into .s files, that can include SIMD instructions. One can also write .s Go assembly files by hand or use something like c2goasm to convert x86 assembly from C programs into Go assembly.
Both those approaches basically work, but are somewhat quirky to use and have some drawbacks. The main purpose of the upcoming simd package is to provide an easy-to-use low-level Go API that together with compiler support facilitates code seamlessly using SIMD instructions without resorting to '.s files and function stubs, which also alleviates or fixes the drawbacks of those approaches.
Over the years, there have been a number of proposals about adding SIMD support through either a higher CPU architecture independent abstraction or by mapping CPU-specific SIMD instructions to lower-level functions.
None of those proposals were accepted by the proposals committee. However, things are starting to look really promising since this proposal recently reached “Likely Accept” status.
The approach of the proposal group is to start by providing a low-level simd package exposing typical SIMD instructions in a CPU-architecture agnostic API, while later adding a higher-level API on top of the lower-level API with more use-case oriented functionality. I guess something like Dot-product or certain cryptographic operations are likely candidates.
An early implementation of the simd package is available for everyone to experiment with, only supporting the amd64 GOARCH - e.g. Intel/AMD x86 processors having SSE, SSE2, AVX, AVX2 and/or AVX512 SIMD extension support.
In order to try out this locally before a production release of Go with GOEXPERIMENT=simd (maybe Go 1.26?), one can install gotip that allows running the latest-and-greatest go command either from the main branch or some other branch.
Start by installing gotip:
go install golang.org/dl/gotip@latest
Then, use the dev.simd branch:
gotip download dev.simd
Now, either you can alias go with gotip, or just type gotip for any go commands you’d otherwise use go for:
gotip run main.go
gotip mod tidy
gotip build -o main main.go
gotip get -u ./...
... and so on ...
On my Mac, gotip installed the dev.simd Go SDK into ~/sdk/gotip.
This is more of a moot point. I normally use IntelliJ with its Go plugin, so how to set-up VSCode to use the Gotip-installation was something I didn’t figure out.
For IntelliJ, I could get some kind of partial code-completion and ability to run code using the simd package by setting GOROOT to the dev.simd SDK installed at ~/sdk/gotip and also setting the appropriate experiment/build tags:
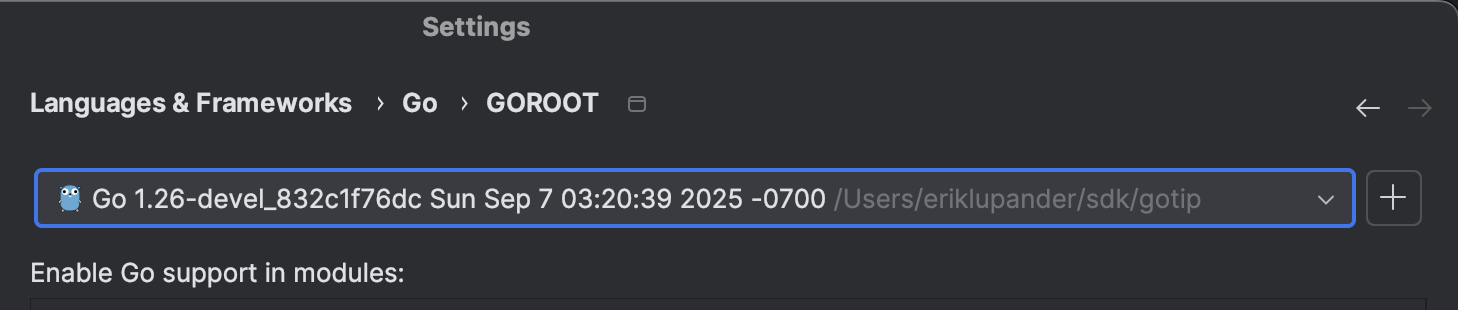
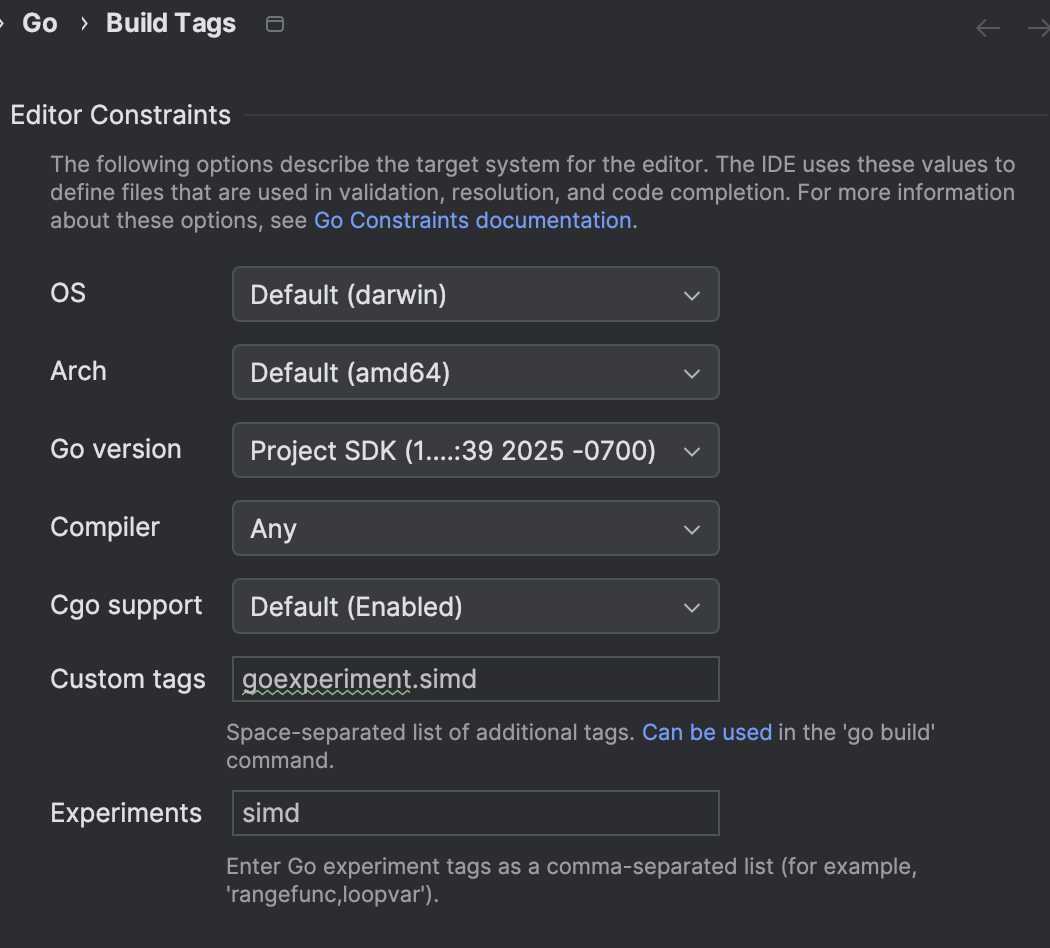
In the introduction, we used a simple element-wise addition as an example:
[2,4,6,8] +
[3,5,7,9]
=
[5,9,13,17]
With the simd package, adding two vectors together with SIMD instruction support is quite low-level but still much easier to understand than raw Go assembly:
//go:build goexperiment.simd && amd64
package main
import "simd"
// SimdAddUint8 performs element-wise addition of the first 32 elements of a and b, storing the outcome in result.
func SimdAddUint8(a, b, result []uint8) {
aInRegister := simd.LoadUint8x32((*[32]uint8)(a)) // Load 32 elements of slice a into a AVX2 register, note the semi-ugly type conversion.
bInRegister := simd.LoadUint8x32((*[32]uint8)(b)) // Load 32 elements of slice b into a AVX2 register
resultInRegister := aInRegister.Add(bInRegister) // Perform the vector add operation
resultInRegister.Store((*[32]uint8)(result)) // Store the result of the addition in the result slice
}
Note that we simply import simd just like any other package. The //go:build goexperiment.simd && amd64 is required for now since the simd package is experimental.
As seen, the low-level simd API doesn’t operate directly on Go slices or arrays, the contents of slices and arrays needs to be loaded into SIMD registers using the various simd.Load* functions. Likewise, the result of the addition is stored in a register and needs to be stored back into program memory using a Store method.
The simd package defines discrete types for various vector types. A few examples:
Uint8x32: Can contain up to 32 uint8 in a 256-bit wide AVX2 register.Int32x4: Can contain up to 4 int32 in a 128-bit wide AVX register.Float64x8: Can contain up to 8 float64 in a 512-bit wide AVX512 register.These types implement a plethora of SIMD functionality using methods, that the dev.simd compiler will generate optimized possible inlined assembly for.
As per plain Go 1.25 - if you want to use assembly of some kind, you need separate .s files with assembly code and Go files with function stubs. This has (at least) one major drawback - Go assembly functions loaded from separate .s files cannot be in-lined. I.e - even a really short assembly snippet such as the “addition” one above, needs to be called as a Go function with all the overhead associated with passing arguments, stack frame allocation etc. which incurs a substantial performance overhead especially for simple functions.
func main() {
_ = Calc(4,5) // outputs 9
}
func Calc(a, b int) int {
return addIfEven(a, b)
}
func addIfEven(a, b int) int {
if a % 2 == 0 {
return a + b
}
return a
}
The Go compiler will typically inline the contents of addIfEven into Calc, and then it may even inline Calc directly into main() when compiling to assembly.
One can check this by supplying -gcflags="-m" when building:
gotip build -gcflags "-m" main.go
... other info omitted ...
./main.go:132:18: inlining call to addIfEven
./main.go:12:13: inlining call to Calc
... other info omitted ...
This effectively removes the overhead of making function calls.
One of the promising things about the new simd package is that the compiler will be able to generate Go assembly using SIMD CPU instructions as first-class citizens, i.e. no separate .s files or function stubs, and the code will be inlinable just like any other code the compiler decides is optimizable.
Let’s benchmark a number of methods for vector-based addition we have looked at above. We’ll do vector addition for slices containing 32 uint8 elements each, using Go’s built-in benchmarking support.
The five variants are:
for loop, with the function decorated with //go:noinline that prohibits inlining.for loop.simd package, with the function decorated with //go:noinline.simd package.Remember - the VPADDB instruction will be able to add 32 uint8s at a time while the plain for-loop just adds one element at a time.
The benchmark function:
// Trick to make sure the Go compiler does not optimize away
// the calls to AddVecUint8
var Result []uint8
func TestMain(m *testing.M) {
m.Run()
fmt.Printf("%v\n", Result) // Prints [2,4,6,8, ...] etc. after test completion, proving that AddVecUint8 was indeed called.
}
func BenchmarkAddVecUint8(b *testing.B) {
x := []uint8{1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8}
y := []uint8{1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8}
ret := make([]uint8, 32)
for i := 0; i < b.N; i++ {
AddVecUint8(x, y, ret) // We just change which function to call here
}
Result = ret // Assign result so the Go compiler does not optimize away anything.
}
Benchmarking the five variants using gotip test -bench=. results in the following, sorted from slowest to fastest:
BenchmarkPlainAddVecUint8NoInline-16 71229476 17.48 ns/op
BenchmarkPlainAddVecUint8-16 135735945 8.843 ns/op
BenchmarkSimdAVOAddUint8-16 428156367 2.765 ns/op
BenchmarkSimdAddUint8NoInline-16 1000000000 1.941 ns/op
BenchmarkSimdAddUint8-16 1000000000 0.4811 ns/op
avo SIMD-enabled code path cannot be inlined since it’s called through a function stub and a .s file, but still performs about 3x better than the inlined “plain” for-loop.simd package with inlining turned off performs ~30% better than the avo solution, probably due to the simd-updated Go compiler generating better optimized assembly under the hood.simd solution with inlining just blows the other solutions out of the water, being more than 4x faster than the closest competitor and something like 16x faster than the plain Go for-loop. I’ll admit, ~0.5 ns/op is suspiciously low, making me suspect some compiler optimization (see next paragraph) messing things up. Nevertheless, our vector addition, when inlined, is basically loading 32+32 bytes into two registers using VMOVDQU, performing a single VPADDB and then a single VMOVDQU to store it back. If those 32 bytes sits in the CPUs L1 cache, perhaps it’s not unreasonable a single op can take half a nanosecond. Well, at least its a lot faster than the for-loop we started with!Benchmarking using go test -bench is powerful, but it can be prone to unexpected results since the compiler very well may optimize away calls it sees as ineffectual. Assigning to var Result []uint8 at the end of the benchmark function is a known workaround for making sure code isn’t optimized out. In Go 1.24, for b.Loop() { was introduced as a way to get more realistic and consistent results, though it has some problems of its own, including removing all inlining of code being benchmarked. Since one of the key points of the simd solution IS to get inlinable SIMD assembly, using b.Loop() is kind of meaningless in this context.
Auto vectorization is when a compiler can detect code during compilation suitable for SIMD optimization, without the developer having to explicitly write vectorization specific code. GCC has some provisions for this, but the Go compiler has never gotten any auto-vectorization support. This is likely due to several reasons, some outlined in an old message on the go-nuts mailing list.
When compiling programs using either standalone assembly, or in this case, assembly generated by the Go compiler from experimental code, one should be aware that tooling may not be entirely output what one would expect.
I wanted to assert that the simd code had indeed been inlined and that it was using the VPADD instruction.
One way to look at Go assembly is to build a binary and then use go tool objdump to study its assembly. Below is an excerpt from gotip build main.go && gotip tool objdump -S -gnu main of the SimdAddUint8 function.
gotip build main.go && gotip tool objdump -S -gnu main
... omitted ...
aInRegister := simd.LoadUint8x32((*[32]uint8)(a))
0x10a2dd1 4c8d442468 LEAQ 0x68(SP), R8 // lea 0x68(%rsp),%r8
0x10a2dd6 c4c17e6f00 VMOVDQU 0(AX), X0 // vmovdqu (%rax),%ymm0
bInRegister := simd.LoadUint8x32((*[32]uint8)(b))
0x10a2ddb 4c8d442448 LEAQ 0x48(SP), R8 // lea 0x48(%rsp),%r8
0x10a2de0 c4c17e6f08 VMOVDQU 0(AX), X1 // vmovdqu (%rax),%ymm1
resultInRegister := aInRegister.Add(bInRegister)
0x10a2de5 c5fdfc CLD // cld
0x10a2de8 c190c5fe7f0231 RCLL $0x31, 0x27ffec5(AX) // rcll $0x31,0x27ffec5(%rax) <-- CHECK THIS!!!
resultInRegister.Store((*[32]uint8)(result))
0x10a2def c0e9ab SHRL $0xab, CL // shr $0xab,%cl
... omitted ...... omitted ...
Assembly for the two simd.LoadUint8x32 calls seems reasonable, but the assembly for resultInRegister := aInRegister.Add(bInRegister) makes no sense at all. What does the RCLL (some variant of “Rotate and carry left”) instruction have to do with AVX2 vector addition? I’m not an assembly guy, so I spent the better part of an hour trying to figure out whether the Go compiler was doing something extremely smart or if I was being very stupid. Even after turning off all compiler optimizations using -gcflags -N -I I could still not make any sense of why RCLL was used where I’d expect VPADDB.
Finally, I remembered that one can instruct go build to output assembly directly to STDOUT using the -S flag:
gotip build -gcflags "-S" main.go
... other code omitted
0x001f 00031 (/Users/eriklupander/privat/simd/main.go:135) VMOVDQU (AX), Y0
0x0023 00035 (/Users/eriklupander/privat/simd/main.go:136) VMOVDQU (DI), Y1
0x0027 00039 (/Users/eriklupander/privat/simd/main.go:137) VPADDB Y1, Y0, Y0 <-- HERE!!!
0x002b 00043 (/Users/eriklupander/privat/simd/main.go:138) CMPQ R10, $32
0x002f 00047 (/Users/eriklupander/privat/simd/main.go:138) JCS 56
0x0031 00049 (/Users/eriklupander/privat/simd/main.go:138) VMOVDQU Y0, (R9)
... other code omitted
Much better! We clearly see VMOVDQU being used to load slice elements into AVX2 YMM registers, VPADDB for the addition and finally VMOVDQU again to store the result in the results parameter denoted as R9 in the listing above.
Why is this? To be honest, I have no idea. Maybe I’m using gotip tool objdump incorrectly, or maybe go tool objdump in the context of this early experiment isn’t updated to correctly print these instructions. No idea. But for now, I will be using go build -S to look at generated assembly.
The experimental simd package is a “Likely Accept” and we can already see that for a simple use-case such as element-wise adding of two 32-element uint8 vectors, there are huge performance gains to be had with a reasonable code complexity cost. Note though that adding two Uint8x32 vectors might be somewhat of a “best-case” scenario.
So, we have a shiny new hammer. What nails should we bang with it? Hopefully, I can revisit this topic soon with a few basic SIMD examples and something more practical.
Until next time!