Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn


Magnus Larssons bok har kommit ut med en 4:e upplaga och vi är lite nyfikna på vad den innehåller och hur är det egentligen att skriva en bok? Vi lyssnar med Magnus vad han säger.

När kom första upplagan ut?
Det var i september 2019.
Hur många exemplar har det sålts av den hittills?
Till och med halvåret 2025, dvs innan 4’e utgåvan släpptes, har det sålts ca 15 000 digitala och fysiska exemplar. Sedan finns det rätt många som läser boken via en prenumeration, vilket inte räknas in i sålda exemplar.
Har du någon aning om hur mycket tid du lagt ner på 4 upplagor sammanlagt?
Nej, det vill jag helst glömma.
Vilka olika steg måste man gå igenom innan en en ny utgåva är klar?
I huvudsak kan man dela in arbetet i tre olika delar:
Planeringsfas
Här jobbar jag i huvudsak själv med att testa ut nya versioner av t ex Spring Boot för att testa ut nya funktioner som jag vill beskriva i en ny utgåva av boken. Med målet att få ut en ny upplaga nära efter en ny release, så börjar jag testa så fort den första milstens releasen finns tillgänglig av t ex en ny Spring Boot version. Det kan bli rätt rörigt att testa milstens-releaser, ofta görs det många förändring där alla inte hunnit slå igenom överallt och därmed orsakar buggar. Men varje kapitel i boken har en fullt automatiserad byggprocess som testar allt från enhetstester till end-to-end tester. Så det är lätt för mig att identifiera buggar i milstens-releaser och de jag hittar rapporterar jag tillbaka till berörda team.
Planeringsfasen avslutas med att jag och förlaget skriver på ett kontrakt om vilka ändringar som skall ingå i den nya upplagan samt en ungefärligt tidplan för när respektive kapitel skall vara färdigt för en draft review.
Skrivfas
Till skrivfasen försöker jag ha all källkod för den nya upplagan så färdig som möjligt för att kunna fokusera på att uppdatera texten i bokens kapitel. När jag är klar med ett kapitel så skickar jag in det till förlaget som en draft version. Hos förlaget finns en person som jag jobbar tillsammans med under hela processen och som ser över struktur och innehåll i kapitlet. Hen kommer med förbättringsförslag som brukar itereras ett antal varv. Samtidigt finns det en extern teknisk granskare som fokuserar på kodexempel och tillhörande beskrivningar i kapitlet. Den tekniska granskaren ger feedback på om kodexempel är relevanta (t ex inte använder gamla lösningar) samt föreslår bättre sätt att lösa ett visst problem, samt provar att köra igenom kommandona för att testa kapitlets kodexempel. Här blir det ofta också en diskussion om vilka ändringar som är relevanta att göra, kan lätt blir lite personberoende vad man tycker är bäst lösning.
Produktionsfas
När alla draft versioner av alla kapitel är godkända lämnas dom över til ett produktionsteam som gör följande:
Dessutom kör man igenom alla exempel i boken en gång till för att säkerställa att inga fel uppstått under produktionsfasen.
Det hela avslutas med att jag får en preview av boken att läsa igenom och upptäcker jag några fel som insmugit sig i texten under produktionsfasen så kan jag ge feedback på det.
För de tidigare utgåvorna av boken så var produktionsfasen ganska utdragen i tiden, men i samband med den nya utgåvan så införde förlaget en ny och betydligt snabbare process för detta steg. Dessvärre visade det sig att den hade vissa inkörningsproblem, jag fick väldigt snabbt tillbaka färdiga så kallada pre-final kapitel men dessvärre hade dom inledningsvis väldigt många fel. Till exempel hade språket i vissa stycken förvisso förbättrats men dess betydelse hade blivit förvanskade. Formateringar som jag gjort för att markera nyckelord, källkod, tips, extra info, länkar mm var borta. Efter en frustrerande period mitt i sommaren fick förlaget till slut ordning på sina processer och för framtida upplagor ser jag fram emot en väloljad och effektiv produktionsfas!
Vad skiljer den 4:e upplagan från tidigare?
Den fjärde upplagan är baserad på Spring Boot 3.5.0 och Spring Cloud 2025.0.0. Spring Boot 3.5 är den sista minor versionen av Spring Boot 3.x. Som vanligt i Spring världen så får den sista minor versionen en extra lång supportperiod och därmed får vi som använder Spring Boot mer tid att förbereda oss inför nästa stora uppgradering till Spring Boot 4.0, se Spring Boot support plan:
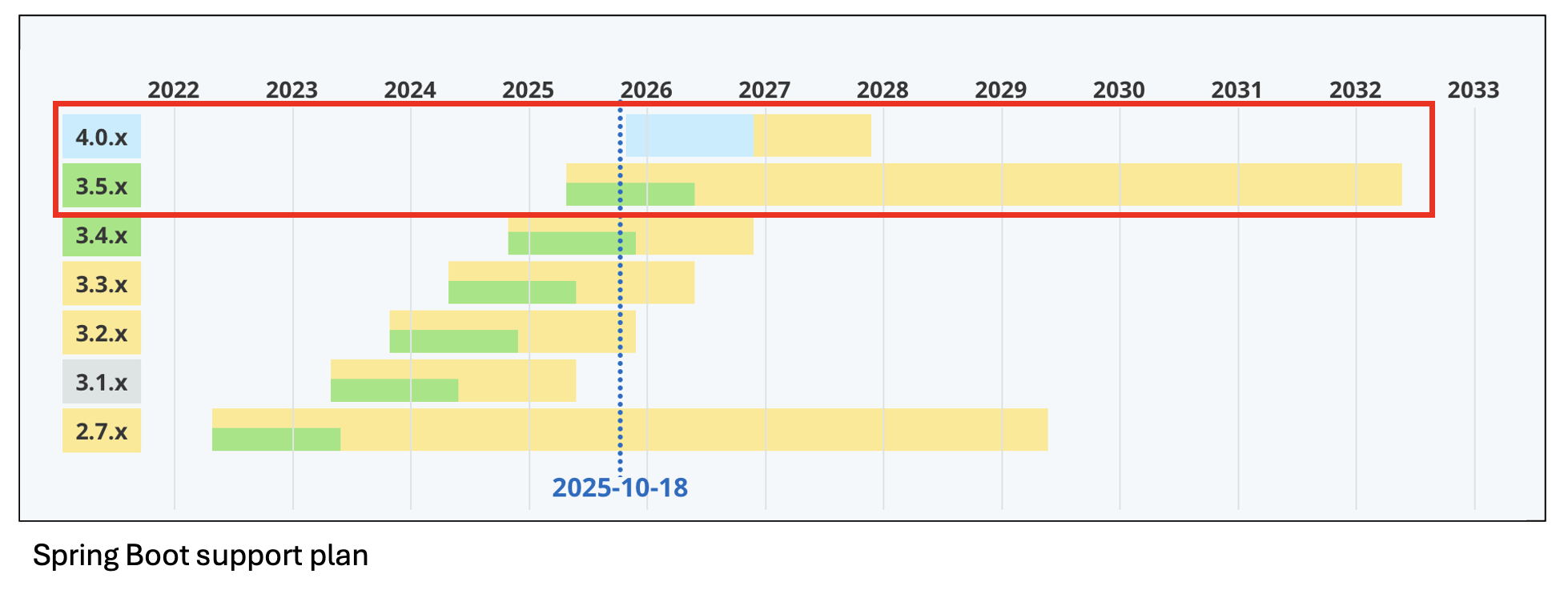
Snart är det dags för nästa major version, Spring Boot 4, med många intressant nyheter men också med en hel del förändringar som man måste göra i sina Spring Boot applikationer för att kunna använda Spring Boot 4.
För att underlätta övergången till Spring Boot 4 så har man i Spring Boot 3.5 deprekerat de metoder som kommer försvinna i Spring Boot 4. Jag rekommenderar därför att man först uppgraderar sina Spring Boot applikationer till 3.5 och säkerställer att man inte använder några deprekerade metoder i Spring Boot.
Som en förberedelse inför Spring Boot 4.0 har många föråldrade API:er fasats ut sedan version 3.0. All källkodsexempel i den här upplagan av boken har uppdaterats till att inte använda några deprekerade metoder i Spring Boot och är därmed förberedd för en uppgradering till den kommande Spring Boot 4 versionen.
Dessutom har alla övriga verktyg som används i boken uppdaterats till sina senaste versioner, inklusive Java, Docker, Minikube, Kubernetes, Istio och Kafka.
Det känns som den tänkta målgruppen har tagit emot denna upplaga på ett bra sätt, jag har t ex fått många positiva reaktioner på LinkedIn.
Hur skiljer sig den här boken från andra böcker om mikrotjänster?
De flesta andra böcker specialiserar sig inom ett viss område, t ex
Jag försöker täcka in alla aspekter, dvs beskriva hur man går från ax till limpa med konkreta kodexempel där jag täcker in allt från hur man utvecklar mikrotjänster från grunden till hur man driftsätter och övervakar i runtime. Bokens kodexempel bygger en litet systemlandskap baserat på fyra samverkande mikrotjänster. För varje kapitel läggs det på ny funktionalitet i systemlandskapet.
Boken är uppdelad i tre delar:
Den första delen handlar om hur man bygger grundläggande funktionalitet så som databaslagring och hur man kommunicerar synkront (REST baserade APIer beskrivna enligt OpenAPI specifikationen) och asynkront (skickar meddelanden mha RabbitMQ och Kafka) mellan mikrotjänster, samt hur man kan automatisera end-to-end tester av ett mikrotjänstlandskap lokalt mha DOcker Compose.
Andra delen av boken går igenom hur man kan bygga stödtjänster för ett mikrotjänstlandskap med hjälp av bland annat Spring Cloud i form av konfigurationshantering, service discovery, API-gateway, distribuerad spårning och övervakning med mera. Man får också lära sig hur man bygger in säkerhet i sina mikrotjänster mha bla OAuth 2 samt hur man kan hantera och minimera effekten av olika typer av felsituationer i ett systemlandskap mha t ex retry-funktioner och kretsbrytare.
I den tredje delen är det fokus på hur man kan använda infrastruktur som Kubernetes och Istio för att köra och övervaka sina mikrotjänster i runtime. Många av Spring Clouds tjänster som introduceras i den andra delen ersätts med funktionalitet i denna infrastruktur. Denna del täcker också in observerbarhet (dvs loggning, monitorering och distribuerad spårning) mha Kibana/Elasticsearch, Grafana/Prometheus och Istio. Till vissa delar används OpenTelemetry standarden för detta. I ett avslutande kapitel visas hur man kan native kompilera sina mikrotjänster mha GraalVM för att reducera dess uppstartstider rejält.
Finns det några vanlig missuppfattningar kring mikrotjänster?
Många utvecklare antar att införandet av mikrotjänster mer eller mindre automatiskt leder till bättre skalbarhet och kortare utvecklingstider. Även om det är enkelt att skapa en enskild mikrotjänst kan det över tid bli komplext att underhålla ett växande systemlandskap av samverkande mikrotjänster.
Ett vanligt misstag är att bryta ner applikationer i för många små tjänster för tidigt. Detta leder ofta till ökad komplexitet, prestandaproblem och utmaningar med datakonsistens. Det kan också resultera i höga driftkostnader och onödigt komplicerade DevOps-processer. En överdriven nedbrytning leder ofta till en ökad komplexitet när man vill införa förändringar som påverkar ett antal av mikrotjänsterna, vilket kan resultera i motsatt effekt, dvs en ökad utvecklingstid.
Boken rekommenderar att man börjar med en grovkornig uppdelning av monolitiska applikationer i större delsystem, vanligtvis styrt av domändriven design. Du kan se dem som “minitjänster” i stället för mikrotjänster. Finkorniga mikrotjänster bör införas inom dessa delsystem först när det finns ett tydligt affärsbehov. Kommunikation mellan delsystem bör ske via väldefinierade och stabila API:er, där ett delsystems interna API:er döljs. Detta möjliggör att varje delsystem i systemlandskapet kan utvecklas vidare oberoende av andra delar i systemlandskapet.
Genom att börja med en grovkornig uppdelning av monolitiska applikationer kan dessa utmaningar undvikas, samtidigt som fördelarna med skalbarhet och kort utvecklingstid hos mikrotjänster fortfarande uppnås.
Planerar du nya upplagor framöver?
Ja, tanken är en 5:e upplaga under 2026 baserad på Spring Boot 4. Därefter har jag tänkt mig att göra en del omstrukturering av boken, där en del material som jag inte längre tycker är så aktuell skall ut och ersättas med lite nya ideer som jag gå och funderar på. Hoppas få ut en 6:e utgåva under 2027, men det får ta den tid som behövs.
Spring Boot 4 finns redan i en releasekandidat version, har du provkört den?
Absolut, jag har testat sedan den första milstensreleasen kom i juli. Dessvärre visade de fösta milstensreleasen sig vara allt för omvälvande (och därmed ostabila) så efter några veckors slit fick jag lägga det jobbet på paus tills den första releasekandidaten kom för någon vecka sedan.
En stor nyhet i Spring Boot 4 är att man förbättrar modulariseringen intent i alla Spring projekt. Förhoppningen är att det skall leda till kompaktare Spring Boot applikationer som kräver mindre minne och som går fortare att starta.
Detta leder dessvärre i sin tur till att man behöver ändra en del beroenden i sina byggskript samt att en del paketnamn i Spring projekten är ändrade.
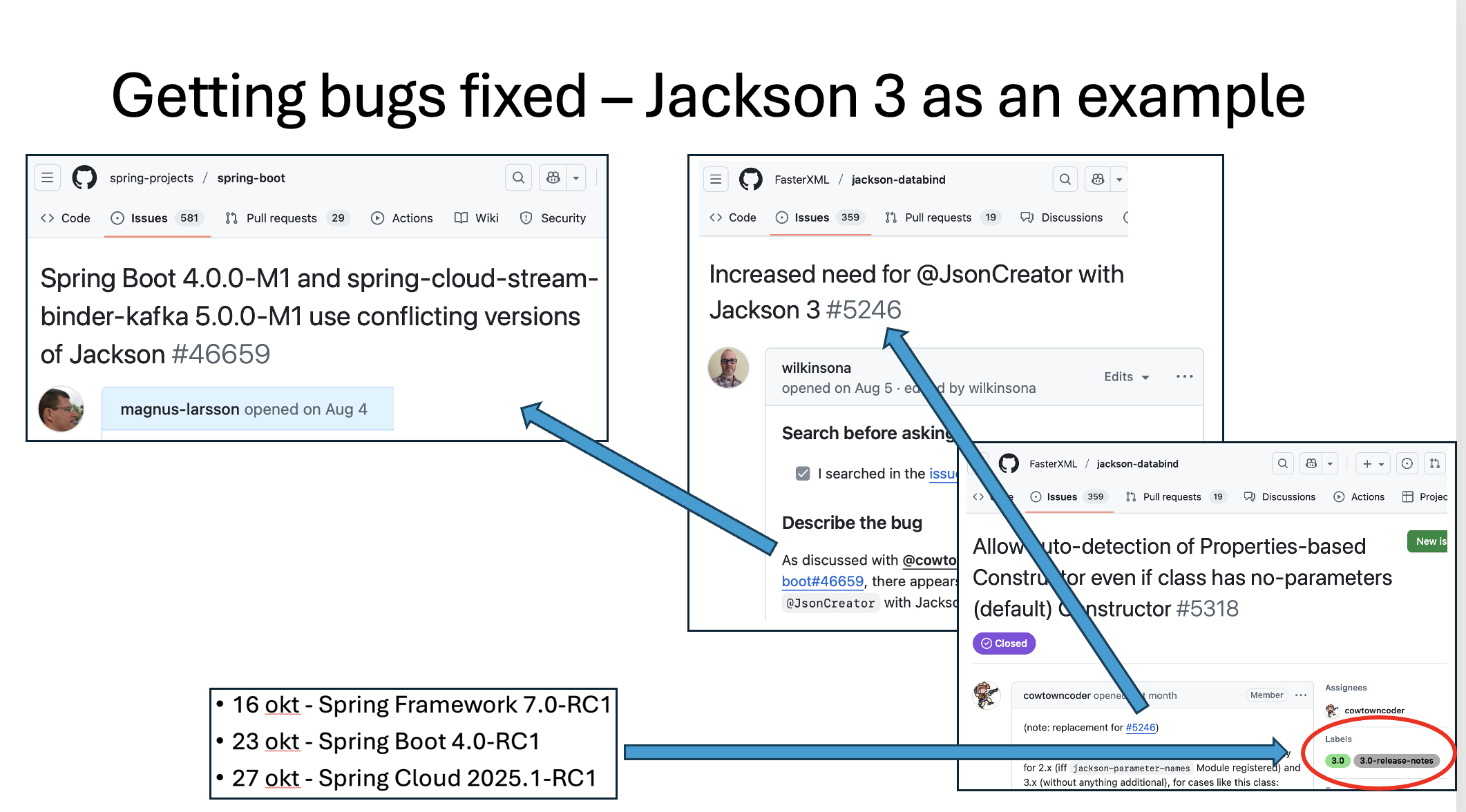
Jag har också hittat en del buggar, bland annat en rätt allvarlig bugg i Jackson 3 som hindrade bakåtkompatibilitet med Jackson 2 (som är utlovad). Jag återskapade buggen i en liten exempelapplikation och skickade in en buggrapport. Det tog ett tag för Spring och Jackson teamen att prata ihop sig, men eftersom jag var tidigt ute och hittade felet redan i den första milstensreleasen så hann felet åtgärdas precis innan GA-releasen av Jackson 3.
Kan du avslöja några nyheter i Spring 4?
Förutom modulariseringen och stödet för Jackson 3 som nämns ovan, så tycker jag att deras arbete med “null-safe applications”, dvs att minimera risken för att det skall uppstå NullPointerExceptions är väldigt intressant. Det bygger på en relativt ny standard som heter JSpecify och som stöds såväl av IDE’er som byggverktyg. Andra saker som verkar intressant är utökat stöd för OpenTelemetry, versionshantering av APIer, samt stöd för Java 24’s AOT Cache (bygger vidare på App CDS) som ger snabbare uppstartstider utan krångel som introduceras av andra teknologier så som CRaC och GraalVM native kompilering.
För intresserade rekommenderar jag att läsa igenom blog poster som nämns här: The Road to GA - Introduction
Tack Magnus, vi ser fram emot att höra mer kring Spring 4 framöver