Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

Vi på Callista gillar att prata om saker som ligger i teknikens framkant, vi gillar att jobba med saker i teknikens framkant. Det finns dock saker som inte verkar försvinna oavsett hur ”långt ut på kanten” man är. I år gick jag inte på de stora “heta” ämnena om bland annat Microservices, Containers och Java updates på Jfokus 2020. Den här gången kände jag mig mer intresserad av att få inspiration kring hur man hanterar problem som man nästan stöter på dagligen.
Jag såg snabbt en röd tråd i ett gäng presentationer under främst första dagen av konferensen och bestämde mig för att kolla in dom. Det började med Livekodning i Live Refactoring Session: Getting rid of dirty code, som sedan följdes av Technical deb: Symptoms root causes and remedies, Continous Profiling in Production: What Why and How samt Continuous Visibility: No more dashboards.
Gemensamt tema här på ett eller annat sätt var “legacy”, legacy systems, legacy code etc. I ett föredrag på Jfokus 2019 påstod Marcus Walter på King att dom inte hade någon legacy code alls på King. Vad är då “legacy”? Min egen definition av legacy code är att det är det där tråkiga och gamla som ingen vill hålla jobba med, antagligen för att man är rädd för att ta sönder något.
En variant av legacy code är teknisk skuld. Teknisk skuld kan uppstå i princip efter man skrivit koden. Steget att gå tillbaka till kod man skrev nyligen och börja skriva om den är inte långt. Teknisk skuld kan man dela upp i olika typer såsom:
På föredraget Technical debt: Symptoms, root causes and remedies pratade Martin Bäumer om Martin Fowler´s “Technical Debt Quadrant” som ofta används när man pratar om teknisk skuld.
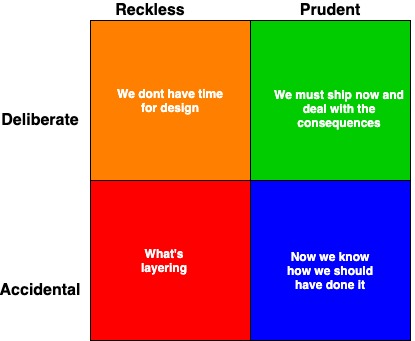
Kvadraten är uppdelad i fyra olika delar. De delarna till vänster, röd och orange, är de sämsta medan de till höger, grön och blå, är att föredra.
Många presentationer handlade indirekt om olika typer av teknisk skuld och hur man hanterar det. Det var resor som började i team eller system som i ovan nämnda kvadrat var röda som sedan gick igenom ett antal steg för att komma till grön/blå. För att komma dit hade man:
På det stora hela handlade det om att man bör förvänta sig att problem kommer att uppstå och hur man kan hantera det. Både innan problemen uppstår, när problemen är live och när problemen ”försvunnit”. Går det att hitta en nivå som man anser sig kunna klara av? Till vilken grad kan man förutspå eventuella problem? Hur kan man lära sig av de problem som uppstått?
Idag finns det en hel uppsjö av verktyg och tekniker för att analysera, förutspå och hantera fel. Trots det känns det som att man fortfarande hanterar stora ”outages” idag på samma sätt som för 10 år sen. Man ägnar fortfarande väldigt mycket tid åt att analysera problem tex genom loggar av olika slag. Det har ju inte blivit svårare att få tag på data på senare år, direkt.
Man ägnar sig även fortfarande åt “Game days” där man simulerar olika kända fel så att man kan lära sig att hantera dem. Dessutom, man gillar fortfarande hängslen och livrem, man bygger gärna upp en on-call verksamhet så att man alltid hade någon beredd att hålla systemet under armarna.
Till slut blir ju de här manuella inslagen en del av den dagliga verksamheten och därmed en sorts teknisk skuld som man vara svår att bli av med.
Det kan ju sluta med att en stackars utvecklare som har on-call blir uppringd 03:30 på en lördagsmorgon för att ”Disc B on Mondeo has low disk space”. Sen får vi se hur kul det kan bli när den lagom glada utvecklaren går in och kör en ”rm *” i ”/backups”.
Det har ju hänt förr, hur hanterar man det?