Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

This part of the blog series will deal with two fundamental pieces of a sound microservice architecture - service discovery and load-balancing - and how they facilitate the kind of horizontal scaling we usually state as an important non-functional requirement in 2017.
While load-balancing is a rather well-known concept, I think Service Discovery entails a more in-depth explanation. I’ll start with a question:
“How does Service A talk to Service B without having any knowledge about where to find Service B?”
In other words - if we have 10 instances of Service B running on an arbitrary number of cluster nodes, someone needs to keep track of all these 10 instances. So when Service A needs to communicate with Service B, at least one proper IP address or hostname for an instance of Service B must be made available to Service A (client-side load balancing) - or - Service A must be able to delegate the address resolution and routing to a 3rd party given a known logical name of Service B (server-side load balancing). In the continuously changing context of a microservice landscape, either approach requires Service Discovery to be present. In its simplest form, Service Discovery is just a registry of running instances for one or many services.
If this sounds a lot like a DNS service to you, it kind of is. The difference being that service discovery is for use within your internal cluster so your microservices can find each other, while DNS typically is for more static and external routing so external parties can have requests routed to your service(s). Also, DNS servers and the DNS protocol are typically not well suited for handling the volatile nature of microservice environments with ever-changing topology with containers and nodes coming and going, clients often not honoring TTL values, failure detection etc.
Most microservice frameworks provides one or several options for service discovery. By default, Spring Cloud / Netflix OSS uses Netflix Eureka (also supports Consul, etcd and ZooKeeper) where services register themselves with a known Eureka instance and then intermittently sends heartbeats to make sure the Eureka instance(s) know they’re still alive. An option (written in Go) that’s becoming more popular is Consul that provides a rich feature set including an integrated DNS. Other popular options are the use of distributed and replicable key-value stores such as etcd where services can register themselves. Apache ZooKeeper should also be mentioned in this crowd.
In this blog post, we’ll primarily deal with the mechanisms offered by “Docker Swarm” (e.g. Docker in swarm mode) and showcase the service abstraction that we explored in part 5 of the blog series and how it actually provides us with both service discovery and server-side load-balancing. Additionally, we’ll take a look at mocking of outgoing HTTP requests in our unit tests using gock since we’ll be doing service-to-service communication.
Note: When referring to “Docker Swarm” in this blog series, I am referring to running Docker 1.12 or later in swarm mode. “Docker Swarm” as a standalone concept was discontinued with the release of Docker 1.12.
In the realm of microservices, one usually differentiates between the two types of load-balancing mentioned above:
Client-side: It’s up to the client to query a discovery service to get actual address information (IPs, hostnames, ports) of services they need to call, from which they then pick one using a load-balancing strategy such as round-robin or random. Also, in order to not have to query the discovery service for each upcoming invocation, each client typically keeps a local cache of endpoints that has to be kept in reasonable sync with the master info from the discovery service. An example of a client-side load balancer in the Spring Cloud ecosystem is Netflix Ribbon. Something similar exists in the go-kit ecosystem that’s backed by etcd. Some advantages of client-side load-balancing is resilience, decentralization and no central bottlenecks since each service consumer keeps its own registry of producer endpoints. Some drawbacks are higher internal service complexity and risk of local registries containing stale entries.
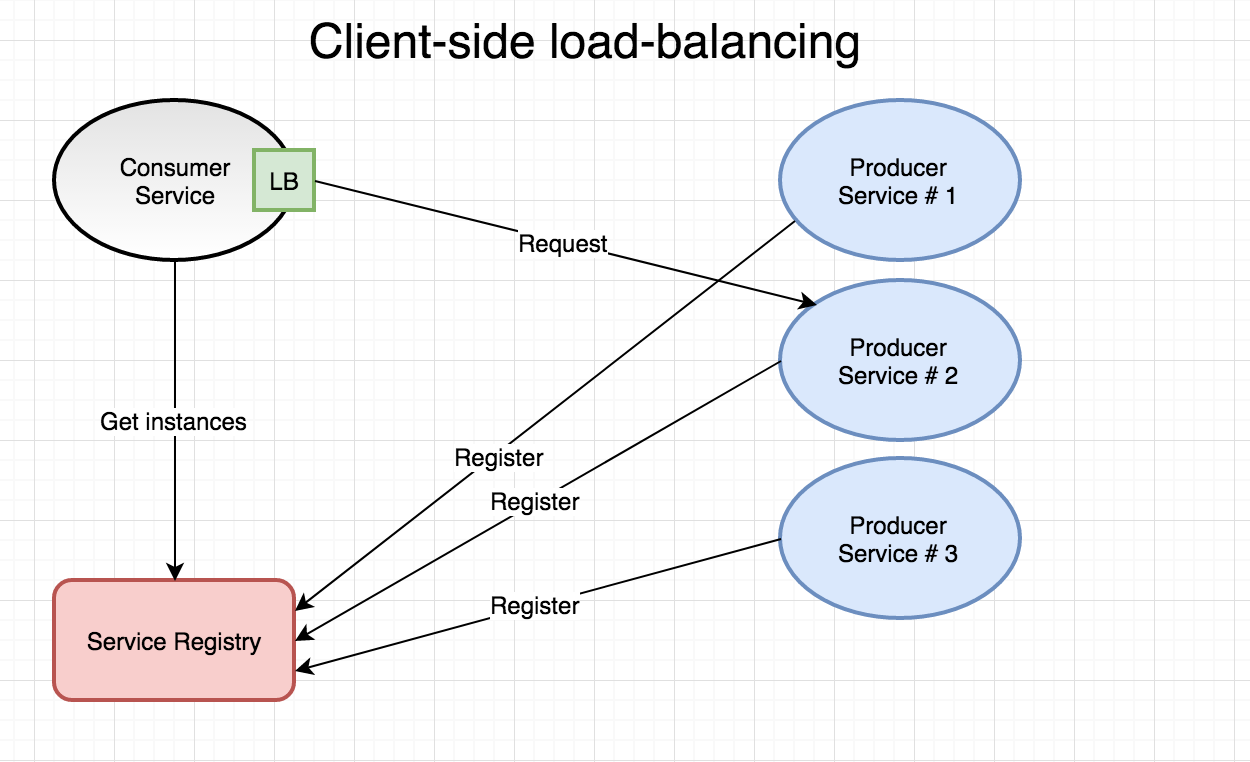
Server-side: In this model, the client relies on the load-balancer to look up a suitable instance of the service it wants to call given a logical name for the target service. This mode of operation is often referred to as “proxy” since it functions both as a load-balancer and a reverse-proxy. I’d say the main advantage here is simplicity. The load-balancer and service discovery mechanism is typically built into your container orchestrator and you don’t have to care about installing or managing those components. Also, the client (e.g. our service) doesn’t have to be aware of the service registry - the load-balancer takes care of that for us. Being reliant on the load-balancer to route all calls arguably decreases resilience and the load-balancer could theoretically become a performance bottleneck.
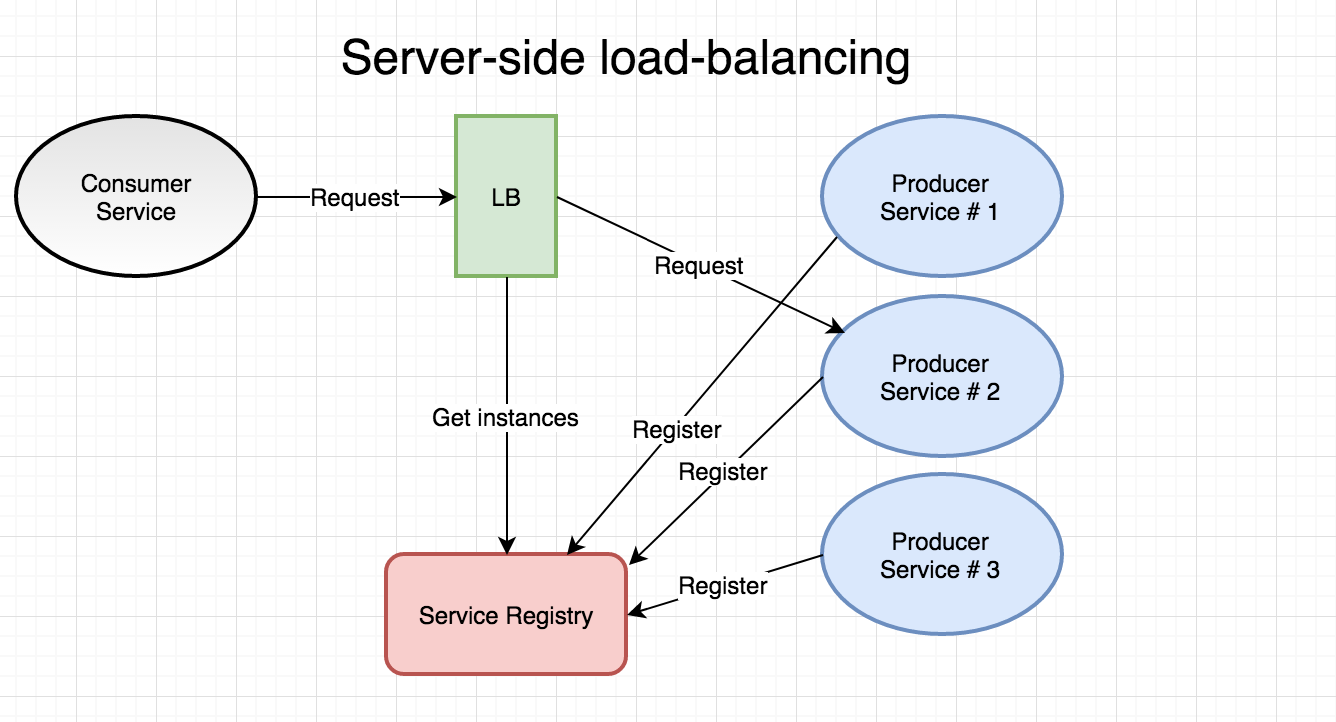
Note that the actual registration of producer services in the server-side example above is totally transparent to you as developer when we’re using the service abstraction of Docker in swarm mode. I.e - our producer services isn’t even aware they are operating in a server-side load-balanced context (or even in the context of a container orchestrator). Docker in swarm mode takes care of the full registration/heartbeat/deregistration for us.
In the example domain we’ve been working with since part 2 of the blog series, we might want to ask our accountservice to fetch a random quote-of-the-day from the quotes-service. In this blog post, we’ll concentrate using Docker Swarm mechanics for service discovery and load-balancing. If you’re interested in how to integrate a Go-based microservice with Eureka, I wrote a blog-post including that subject in 2016. I’ve also authored a simplistic and opinionated client-side library to integrate Go apps with Eureka including basic lifecycle management.
Let’s say you want to build a custom-made monitoring application and need to query the /health endpoint of every instance of every deployed service. How would your monitoring app know what IP’s and ports to query? You need to get hold of actual service discovery details. If you’re using Docker Swarm as your service discovery and load-balancing provider and need those IPs, how would you get hold of the IP address of each instance when Docker Swarm is keeping that information for us? With a client-side solution such as Eureka you’d just consume the information using its API. However, in the case of relying on the orchestrator’s service discovery mechanisms, this may not be as straightforward. I’d say there’s one primary option to pursue and a few secondary options one could consider for more specific use cases.
Primarily, I would recommend using the Docker Remote API - e.g. use the Docker APIs from within your services to query the Swarm Manager for service and instance information. After all, if you’re using your container orchestrator’s built-in service discovery mechanism, that’s the source you should be querying. For portability, if that’s an issue, one can always write an adapter for your Orchestrator of choice. However, it should be stated that using the Orchestrator’s API have some caveats too - it ties your solution closely to a specific container API and you’d have to make sure your application can talk to the Docker Manager(s), e.g. they’d be aware of a bit more of the context they’re running in and using the Docker Remote API does increase service complexity somewhat.
Feel free to checkout the appropriate branch for the completed source code of this part from github:
git checkout P7
Note: Most of the Go source code for the blog series was rewritten in July 2019 to better reflect contemporary idiomatic Go coding guidelines and design patterns. However, the corresponding git branch for each part of the series remains unchanged in order to stay aligned with the content of each installment. For the latest and greatest code, look at the master branch in github.
We’ll continue this part by taking a look at scaling our “accountservice” microservice to run multiple instances and see if we can make Docker Swarm automatically load-balance requests to it for us.
In order to know what instance that actually served a request we’ll add a new field to the “Account” struct that we can populate with the IP address of the producing service instance. Open /accountservice/model/account.go:
type Account struct {
Id string `json:"id"`
Name string `json:"name"`
// NEW
ServedBy string `json:"servedBy"`
}
When serving an Account in the GetAccount function, we’ll now populate the ServedBy field before returning. Open /accountservice/service/handlers.go and add the GetIp() function as well as the line of code that populates the ServedBy field on the struct:
func GetAccount(w http.ResponseWriter, r *http.Request) {
// Read the 'accountId' path parameter from the mux map
var accountId = mux.Vars(r)["accountId"]
// Read the account struct BoltDB
account, err := DBClient.QueryAccount(accountId)
account.ServedBy = getIP() // NEW, add this line
...
}
// ADD THIS FUNC
func getIP() string {
addrs, err := net.InterfaceAddrs()
if err != nil {
return "error"
}
for _, address := range addrs {
// check the address type and if it is not a loopback the display it
if ipnet, ok := address.(*net.IPNet); ok && !ipnet.IP.IsLoopback() {
if ipnet.IP.To4() != nil {
return ipnet.IP.String()
}
}
}
panic("Unable to determine local IP address (non loopback). Exiting.")
}
The getIP() function should go into some “utils” package since it’s reusable and useful for a number of different occurrences when we need to determine the non-loopback IP-address of a running service.
Rebuild and redeploy our service by running copyall.sh again from $GOPATH/src/github.com/callistaenterprise/goblog:
> ./copyall.sh
Wait until it’s finished and then type:
> docker service ls
ID NAME REPLICAS IMAGE
yim6dgzaimpg accountservice 1/1 someprefix/accountservice
Call it using curl:
> curl $ManagerIP:6767/accounts/10000
{"id":"10000","name":"Person_0","servedBy":"10.255.0.5"}
Lovely. We see that the response now contains the IP address of the container that served our request. Let’s scale the service up a bit:
> docker service scale accountservice=3
accountservice scaled to 3
Wait a few seconds and run:
> docker service ls
ID NAME REPLICAS IMAGE
yim6dgzaimpg accountservice 3/3 someprefix/accountservice
Now it says replicas 3/3. Let’s curl a few times and see if get different IP addresses as servedBy.
curl $ManagerIP:6767/accounts/10000
{"id":"10000","name":"Person_0","servedBy":"10.0.0.22"}
curl $ManagerIP:6767/accounts/10000
{"id":"10000","name":"Person_0","servedBy":"10.255.0.5"}
curl $ManagerIP:6767/accounts/10000
{"id":"10000","name":"Person_0","servedBy":"10.0.0.18"}
curl $ManagerIP:6767/accounts/10000
{"id":"10000","name":"Person_0","servedBy":"10.0.0.22"}
We see how our four calls were round-robined over the three instances before 10.0.0.22 got to handle another request. This kind of load-balancing provided by the container orchestrator using the Docker Swarm “service” abstraction is very attractive as it removes the complexity of client-side based load-balancing such as Netflix Ribbon and also shows that we can load-balance without having to rely on a service discovery mechanism to provide us with a list of possible IP-addresses we could call. Also - from Docker 1.13 Docker Swarm won’t route any traffic to nodes not reporting themselves as “healthy” if you have implemented the Healthcheck. This is very important when having to scale up and down a lot, especially if your services are complex and may take more than the few hundreds of milliseconds to start our “accountservice” currently needs.
It may be interesting to see if and how scaling our accountservice from one to four instances affects latencies and CPU/memory usage. Could there be a substantial overhead when the Swarm mode load-balancer round-robins our requests?
> docker service scale accountservice=4
Give it a few seconds to start things up.
Running the Gatling test with 1K req/s:
CONTAINER CPU % MEM USAGE / LIMIT
accountservice.3.y8j1imkor57nficq6a2xf5gkc 12.69% 9.336 MiB / 1.955 GiB
accountservice.2.3p8adb2i87918ax3age8ah1qp 11.18% 9.414 MiB / 1.955 GiB
accountservice.4.gzglenb06bmb0wew9hdme4z7t 13.32% 9.488 MiB / 1.955 GiB
accountservice.1.y3yojmtxcvva3wa1q9nrh9asb 11.17% 31.26 MiB / 1.955 GiB
Well well! Our 4 instances are more or less evenly sharing the workload and we also see that the three “new” instances stay below 10 mb of RAM given that they never should need to serve more than 250 req/s each.
First - the Gatling excerpt using one (1) instance:
 Next - from the run with four (4) instances:
Next - from the run with four (4) instances:

The difference isn’t all that great - and it shouldn’t be - all four service instances are after all running on the same virtualbox-hosted Docker Swarm node on the same underlying hardware (i.e. my laptop). If we would add more virtualized instances to the Swarm that can utilize unused resources from the host OS we’d probably see a much larger decrease in latencies as it would be separate logical CPUs etc. handling the load. Nevertheless - we do see a slight performance increase regarding the mean and 95/99-percentiles. We can safely conclude that the Swarm mode load-balancing has no negative impact on performance in this particular scenario.
Remember that Java-based quotes-service we deployed back in part 5? Let’s scale it up and then call it from the “accountservice” using its service name “quotes-service”. The purpose of adding this call is to showcase how transparent the service discovery and load-balancing becomes when the only thing we need to know about the service we’re calling is its logical service name.
We’ll start by editing /goblog/accountservice/model/account.go so our response will contain a quote:
type Account struct {
Id string `json:"id"`
Name string `json:"name"`
ServedBy string `json:"servedBy"`
Quote Quote `json:"quote"` // NEW
}
// NEW struct
type Quote struct {
Text string `json:"quote"`
ServedBy string `json:"ipAddress"`
Language string `json:"language"`
}
Note that we’re using the json tags to map from the field names that the quotes-service outputs to struct names of our own, quote to text, ipAddress to ServedBy etc.
Continue by editing /goblog/accountservice/service/handler.go. We’ll add a simplistic getQuote function that will perform a HTTP call to http://quotes-service:8080/api/quote whose return value will be used to populate the new Quote struct. We’ll call it from the main GetAccount handler function.
First, we’ll deal with a Connection: Keep-Alive issue that will cause load-balancing problems unless we explicitly configure the Go http client appropriately. In handlers.go, add the following just above the GetAccount function:
var client = &http.Client{}
func init() {
var transport http.RoundTripper = &http.Transport{
DisableKeepAlives: true,
}
client.Transport = transport
}
This init method will make sure any outgoing HTTP request issued by the client instance will have the appropriate headers making the Docker Swarm-based load-balancing work as expected. Next, just below the GetAccount function, add the package-scoped getQuote() function:
func getQuote() (model.Quote, error) {
req, _ := http.NewRequest("GET", "http://quotes-service:8080/api/quote?strength=4", nil)
resp, err := client.Do(req)
if err == nil && resp.StatusCode == 200 {
quote := model.Quote{}
bytes, _ := ioutil.ReadAll(resp.Body)
json.Unmarshal(bytes, "e)
return quote, nil
} else {
return model.Quote{}, fmt.Errorf("Some error")
}
}
Nothing special about it. That “?strength=4” argument is a peculiarity of the quotes-service API that can be used to make it consume more or less CPU. If there are some problem with the request, we return a generic error.
We’ll call the new getQuote func from the GetAccount function, assigning the returned value to the Quote property of the Account instance if there were no error:
// Read the account struct BoltDB
account, err := DBClient.QueryAccount(accountId)
account.ServedBy = getIP()
// NEW call the quotes-service
quote, err := getQuote()
if err == nil {
account.Quote = quote
}
(All this error-checking is one of my least favourite things about Go, even though it arguably produces code that is safer and maybe shows the intent of the code more clearly.)
If we would run the unit tests in /accountservice/service/handlers_test.go now, they would fail! The GetAccount function under test will now try to do a HTTP request to fetch a famous quote, but since there’s no quotes-service running on the specified URL (I guess it won’t resolve to anything) the test cannot pass.
We have two strategies to choose from here given the context of unit testing:
1) Extract the getQuote function into an interface and provide one real and one mock implementation, just like we did in part 4 for the Bolt client. 2) Utilize a HTTP-specific mocking framework that intercepts outgoing requests for us and returns a pre-determined answer. The built-in httptest package can start an embedded HTTP server for us that can be used for unit-testing, but I’d like to use the 3rd party gock framework instead that’s more concise and perhaps a bit easier to use.
In /goblog/accountservice/service/handlers_test.go, add an init function above the TestGetAccount(t *testing) function that will make sure our http client instance is intercepted properly by gock:
func init() {
gock.InterceptClient(client)
}
The gock DSL provides fine-granular control over expected outgoing HTTP requests and responses. In the example below, we use New(..), Get(..) and MatchParam(..) to tell gock to expect the http://quotes-service:8080/api/quote?strength=4 GET request and respond with HTTP 200 and a hard-coded JSON string as body.
At the top of TestGetAccount(t *testing), add:
func TestGetAccount(t *testing.T) {
defer gock.Off()
gock.New("http://quotes-service:8080").
Get("/api/quote").
MatchParam("strength", "4").
Reply(200).
BodyString(`{"quote":"May the source be with you. Always.","ipAddress":"10.0.0.5:8080","language":"en"}`)
defer gock.Off() makes sure our test will turn off HTTP intercepts after the current test finishes since the gock.New(..) will turn http intercept on which could potentially fail subsequent tests.
Let’s assert that the expected quote was returned. In the innermost Convey-block of the TestGetAccount test, add a new assertion:
Convey("Then the response should be a 200", func() {
So(resp.Code, ShouldEqual, 200)
account := model.Account{}
json.Unmarshal(resp.Body.Bytes(), &account)
So(account.Id, ShouldEqual, "123")
So(account.Name, ShouldEqual, "Person_123")
// NEW!
So(account.Quote.Text, ShouldEqual, "May the source be with you. Always.")
})
Try running all tests from the /goblog/accountservice folder:
> go test ./...
? github.com/callistaenterprise/goblog/accountservice [no test files]
? github.com/callistaenterprise/goblog/accountservice/dbclient [no test files]
? github.com/callistaenterprise/goblog/accountservice/model [no test files]
ok github.com/callistaenterprise/goblog/accountservice/service 0.011s
Rebuild/redeploy using ./copyall.sh and then try calling the accountservice using curl:
> curl $ManagerIP:6767/accounts/10000
{"id":"10000","name":"Person_0","servedBy":"10.255.0.8","quote":
{"quote":"You, too, Brutus?","ipAddress":"461caa3cef02/10.0.0.5:8080","language":"en"}
}
Scale the quotes-service to two instances:
> docker service scale quotes-service=2
Give it some time, it may take 15-30 seconds as the Spring Boot-based quotes-service is not as fast as our Go counterparts to start. Then call it again a few times using curl, the result should be something like:
{"id":"10000","name":"Person_0","servedBy":"10.255.0.15","quote":{"quote":"To be or not to be","ipAddress":"768e4b0794f6/10.0.0.8:8080","language":"en"}}
{"id":"10000","name":"Person_0","servedBy":"10.255.0.16","quote":{"quote":"Bring out the gimp.","ipAddress":"461caa3cef02/10.0.0.5:8080","language":"en"}}
{"id":"10000","name":"Person_0","servedBy":"10.0.0.9","quote":{"quote":"You, too, Brutus?","ipAddress":"768e4b0794f6/10.0.0.8:8080","language":"en"}}
We see that our own servedBy is nicely cycling through the available accountservice instances. We also see that the ipAddress field of the quote object has two different IPs. If we hadn’t disabled the keep-alive behaviour, we’d probably be seeing that the same instance of accountservice keeps serving quotes from the same quotes-service instance.
In this part we touched upon the concepts of Service Discovery and Load-balancing in the microservice context and implemented calling of another service using only its logical service name.
In part 8, we’ll move on to one of the most important aspects of running microservices at scale - centralized configuration.