Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

In the last part, we implemented the Schema-per-tenant pattern, and observed that it will scale better than the Database-per-tenant implementation. There will still most likely be an upper limit on the number of tenants it supports, caused by the Database Migrations that has to be applied to each tenant.
In this part, we will redo the solution and implement the Shared database with Discriminator Column pattern using Hibernate Filters and some AspectJ magic.
The Database per Tenant and Schema per Tenant patterns provide a clean separation of data between tenants, but at the price of duplicating the database table definitions for each tenant. As we observed in the last part, this may cause scalability problems, since every Database Migration needed must be applied for every tenant. If Database Migrations are applied automatically on application startup (the default setting for Liquibase migrations with Spring Boot), a large number of tenants will lead to long startup time.
In the Shared database with Discriminator Column pattern, this problem no longer exists. Placing the data for all tenants in one single database, we only have one single set of database to manage.
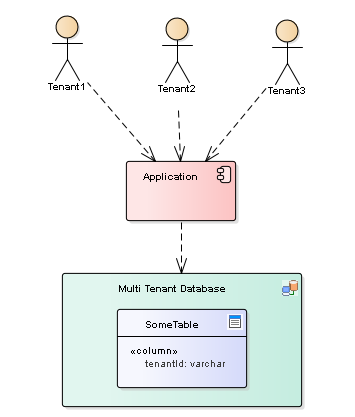
In order to separate data between different tenants, we use a Discriminator Column in every table to hold the tenant information for each row in the table. We would hence need to populate the discriminator column with correct tenant information every time we store data, and we need to include the discriminator column as an extra wherecondition every time we query for data. That is clearly a Cross Cutting Concern that we would like to capture in one single place. The data isolation guarantee between tenants (which our customers most likely will require from us) relies on us being able to prove that the discriminator column is properly used for all database access!
So let’s implement the Shared Database with Discriminator Column pattern using Hibernate Filters!
Although Hibernate’s MultiTenancyStrategy enumeration contains a MultiTenancyStrategy.DISCRIMINATOR entry, this pattern is not yet supported in Hibernate as of version 5.4.x. It was scheduled for version 5, but never made it. There is an open JIRA issue for discriminator-based multi-tenancy, but with no real progress since 2017. The JIRA issue however identifies the existing Hibernate mechanisms available roll our own implementation.
As we observed above, there are two capabilities needed:
where condition on all queries for entitiesLuckily, there are existing mechanisms available for both these capabilities: Standard JPA EntityListener and Hibernate specific Filter.
The standard JPA EntityListener mechanism allows a listener to be attached to the lifecycle of a JPA entity. It allows us to to populate the Discriminator column with the current tenant. Given an interface TenantAware that all entities implement, the following Listener will do the trick:
public interface TenantAware {
void setTenantId(String tenantId);
}
public class TenantListener {
@PreUpdate
@PreRemove
@PrePersist
public void setTenant(TenantAware entity) {
final String tenantId = TenantContext.getTenantId();
entity.setTenantId(tenantId);
}
}
The standard Hibernate Filter mechanism allows us to define a Filter containing a whereclause that can be applied to all queries for entities upon which the Filter is attached:
@FilterDef(name = "tenantFilter", parameters = {@ParamDef(name = "tenantId", type = "string")})
@Filter(name = "tenantFilter", condition = "tenant_id = :tenantId")
We are now prepared to encapsulate the usage of a discriminator column, an EntityListener and a Filter as an abstract base class for our Entities:
@MappedSuperclass
@Getter
@Setter
@NoArgsConstructor
@FilterDef(name = "tenantFilter", parameters = {@ParamDef(name = "tenantId", type = "string")})
@Filter(name = "tenantFilter", condition = "tenant_id = :tenantId")
@EntityListeners(TenantListener.class)
public abstract class AbstractBaseEntity implements TenantAware, Serializable {
private static final long serialVersionUID = 1L;
@Size(max = 30)
@Column(name = "tenant_id")
private String tenantId;
public AbstractBaseEntity(String tenantId) {
this.tenantId = tenantId;
}
}
All entities will need to extend AbstractBaseEntity in order to have the multitenancy support applied, as for example:
@Entity
public class Product extends AbstractBaseEntity {
...
}
That was a neat and self-contained mechanism! However, there is still one piece missing: Unfortunately, a Filter defined on an entity doesn’t get automatically applied, it is only available to be applied. When a query is issued, the underlying Hibernate Session needs to be explicitly configured to use the filter. Since the Session object is created dynamically at runtime (typically once for each transaction), we cannot apply the Filter once and for all at application startup. Instead we need an additional mechanism: an Aspect.
AspectJ provides a mechanism to defined fine-grained execution points and intercept the execution at those points to inject additional behaviour. This is exactly what we need: A way to intercept the creation of a Hibernate Session, to make sure that our Filter is properly applied to every created Session. Note that we cannot to that with the light-weight built in Aspect functionality in Spring, since that mechanism can only be used for Spring-managed beans. The Hibernate Session object is not managed by Spring, and hence we need the full-fledged AspectJ support.
In order to do its magic (intercepting arbitrary code and injecting functionality at runtime), AspectJ needs to weave the defined aspects into the classes that should be affected. The weaving can be done at compile-time (using the AspectJ compiler as a step in the build chain, after Java compilation has completed), or at load-time using load-time weaving. The latter approach is less intrusive, and hence to be preferred in our case.
Configuring the AspectJ Load-Time Weaver is done using an META-INF/aop.xml file in the classpath:
<aspectj>
<weaver options="-Xreweavable -verbose -showWeaveInfo">
<include within="se.callista.blog.service.multi_tenancy.aspect.TenantFilterAspect"/>
<include within="org.hibernate.internal.SessionFactoryImpl.SessionBuilderImpl"/>
</weaver>
<aspects>
<aspect name="se.callista.blog.service.multi_tenancy.aspect.TenantFilterAspect"/>
</aspects>
</aspectj>
This configuration defines an aspect TenantFilterAspect and the classes to which it should apply (in this case org.hibernate.internal.SessionFactoryImpl.SessionBuilderImpl). Note that the Aspect class itself must be part of the weaver classes, for technical reasons.
The TenantFilterAspect is reasonably straight-forward:
@Aspect
public class TenantFilterAspect {
@Pointcut("execution (* org.hibernate.internal.SessionFactoryImpl.SessionBuilderImpl.openSession(..))")
public void openSession() {
}
@AfterReturning(pointcut = "openSession()", returning = "session")
public void afterOpenSession(Object session) {
if (session != null && Session.class.isInstance(session)) {
final String tenantId = TenantContext.getTenantId();
if (tenantId != null) {
org.hibernate.Filter filter = ((Session) session).enableFilter("tenantFilter");
filter.setParameter("tenantId", tenantId);
}
}
}
}
It defines an execution point (using the @Pointcut annotation) for when a new Hibernate session is opened. In this execution point (using the @AfterReturning annotation), it injects the required setup to apply the Hibernate Filter.
Getting AspectJ load-time weaving to work in Spring Boot can be a bit complex, since the documentation is slightly misleading. First thing, we need the AspectJ weaver and Spring Boot aspect support in the classpath which is done easiest using a Spring Boot starter dependency:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
Next step is to enable the AspectJ load time weaver, using the @EnableLoadTimeWeaving annotation:
@SpringBootApplication
@EnableLoadTimeWeaving(aspectjWeaving = EnableLoadTimeWeaving.AspectJWeaving.ENABLED)
public class MultiTenantServiceApplication extends SpringBootServletInitializer {
...
}
Finally, we need to use both Spring’s instrumentation agent and AspectJ’s aspectjweaver agent to be passed as -javaagent JVM arguments. The configuration of java agents will differ depending on deployment scenario. Using the Maven spring-boot plugin, the following configuration will to the work:
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<agents>
<agent>${project.build.directory}/spring-instrument-${spring-framework.version}.jar</agent>
<agent>${project.build.directory}/aspectjweaver-${aspectj.version}.jar</agent>
</agents>
</configuration>
</plugin>
while running the application on the command line would look like this:
java -javaagent:spring-instrument.jar -javaagent:aspectjweaver.jar -jar app.jar
The above implementation is simple and self-contained. The systematic usage of EntityListeners and Hibernate Filters applied via an Aspect seems fairly robust. It will guarantee that each tenant’s data is totally isolated from other tenants (even though the data lives in the same database), won’t it?
Unfortunately, there is one subtle leak: Hibernate’s Filter mechanism is designed to apply to all Hibernate queries, but not to direct fetching via the Session object (using session.find(<id>)). The implementation of findById() in Spring Data’s SimpleJpaRepository indeed by default uses em.find(...) under the hood, and therefore will not be affected by the filter. Hence will allow fetching entities that belong to other tenants!
Fixing this problem is indeed easy, just override the findById() with a proper JPQL query:
public interface ProductRepository extends CrudRepository<Product, Long> {
@Query("SELECT p from Product p WHERE p.id = :id")
Optional<Product> findById(long id);
}
Simple, yes, but the problem is you have to know it must be done for each and every Repository used!
We now have a straight-forward implementation of the Shared Database with Discriminator Column pattern. Since we now use one single Database, the need for specific on-boarding logic and Migrations for tenants disappeared, as did most of the configuration. The use of AspectJ and load-time weaving is however a thing that not everyone may feel comfortable with.
A fully working, minimalistic example can be found in the Github repository for this blog series, in the shared_database_hibernate branch.
The Shared Database with Discriminator Column pattern implementation overcomes the scalability issues we identified with the previous implementations. Hence we can assume this implementation will no practical limitation on the number of tenants (rather the scalability of the database itself will likely be the bottleneck).
The data separation guarantee between tenants however now becomes a challenge. The implementation is based on several cooperating mechanisms which may have leaks of their own or in combination with the other mechanisms. The burden of proof lies on us that there are no leaks.
In the next part, we’ll instead implement the critical Filter part of the solution using an advanced database mechanism: Row Level Security. Stay tuned!
The following links have been very useful inspiration when preparing this material:
medium.com/@vivareddy/muti-tenant-with-discriminator-column-hibernate-implementation-a363f03b1d10
github.com/ramsrib/multi-tenant-app-demo