Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

In part one we looked at some of the popular schema frameworks used with Kafka. In part two we will look at the role of the Schema Registry.
Now that we have structured our data with a schema we can use a Schema Registry for three purposes:
In this blog we will look at the first two, schema evolution will be discussed in a later blog post.
Part two continues with the Weather Reporting example presented in part one, which can be found in this GitHub repository. The application uses the Quarkus framework and the focus of this blog will be on Java.
The schema registry is not a part of the Apache Kafka platform itself but is often bundled with Kafka plaftorm offerings; Confluent Platform offer the Confluent Schema Registry, Redpanda offer the Redpanda Schema Registry, Aiven use Karapace. In this example we will look at the Apicurio Registry for the simple reason that it is tightly associated with Quarkus and TestContainers.
Note that schema registries are not seamlessly interchangeable - they offer similar APIs and often some level of compatibility. In this example the Quarkus Dev Services will use the Apicurio registry in dev mode, but could use the Confluent Schema Registry in production mode by providing alternative configuration. The reader is challenged to take the example application and to switch to the Confluent Schema registry using the provided instructions.
The example application can be considered a code-first approach to using the schema registry - the schemas are not made available to the registry prior to their use by a client application (producer or consumer). The source code contains schemas in the JSON-Schema, Avro and Protobuf formats which are made available to the Schema Registry at runtime.
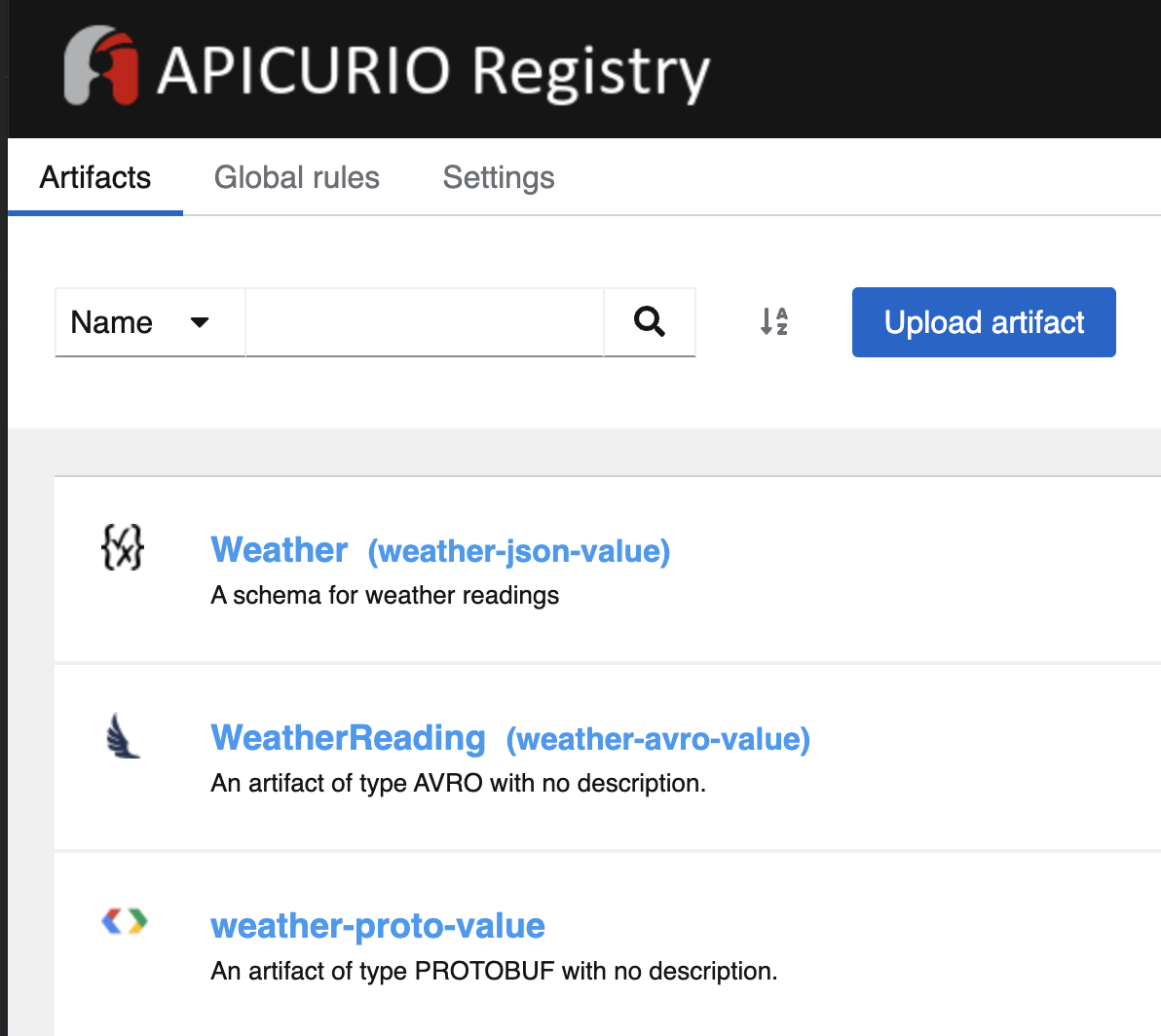
Starting the application, either in dev or prod modes, will kick off the producers and consumers. If we take a look at the Apicurio registry we can see three schemas have been published:
Let’s take a deeper look at the Avro example where we want to ensure that messages follow the schema in /src/main/weather-schema.avsc. Quarkus provides detailed documentation for setting up an Avro integration. At runtime the configuration is going to perform the Schema magic which for the consumer (ìncoming) and producer (outgoing) looks like this:
%prod.mp.messaging.connector.smallrye-kafka.apicurio.registry.url=http://schema-registry:8080/apis/registry/v2
mp.messaging.outgoing.out-weather-avro.apicurio.registry.auto-register=true
mp.messaging.outgoing.out-weather-avro.value.serializer=io.apicurio.registry.serde.avro.AvroKafkaSerializer
mp.messaging.incoming.in-weather-avro.value.deserializer=io.apicurio.registry.serde.avro.AvroKafkaDeserializer
This configuration:
dev provided by the Quarkus Dev Services).auto-register=true).…and for our simple example we have Avro serialization and deserialziation ready out of the box where we know that the objects serialized on the topic follow our defined schema. There are, however, a few things to consider before we close the ticket and move onward to something else, and one of the important questions we should always ask ourselves is…
This is a difficult question to answer.
For serialization we are relying on the AvroKafkaSerializer class to publish the schema and to enforce the schema. In this case this is part of the Quarkus framework, which utilizes the SmallRye Reactive Messaging library, which in turn relies on the weak link, our own configuration.
For fun, I have provided an alternative custom serializer called CustomWeatherSerializer that simulates a rogue producer which you can configure as a replacement for the AvroKafkaSerializer. This serializer will happily publish a non-Avro message to the topic which the consumer will not be able to handle.
The rogue producer is used to illustrate the looseness of the schema guarantees here. If the configuration has been done correctly:
Note: there is no guarantee that the consumer and producer are enforcing conformity to the same schema, which is useful when evolving schemas, but can cause problems if one of the two switches unexpectedly.
Note that there are no guarantees:
These guarantees can be strengthened by reducing access to the topics, both for consuming and producing, to avoid unknown rogue processes from trying to use your topics.
Automated testing at build time may improve your confidence but there is a fine line between testing your own application and testing the underlying framework. Learning what your framework offers in terms of protection is essential to provide peace of mind. Manual verification in production is likely to be essential.
If we start the application and take a look in Apicurio we can see three schemas:
weather-json-value with name Weather and content that matches the JSON-Schema in weather-schema.jsonweather-avro-value with name WeatherReading and content that is semantically equivalent, but not the same as, the Avro schema in weather-schema.avscweather-proto-value with no name and content that is semantically equivalent, but not the same as, the Protobuf schema in weather-report.protoWhere did these names come from? The Quarkus default configuration uses the TopicIdStrategy to generate identities for the Schema Repository artifacts, which is the topic name suffixed with -value for the value of the record. As the auto-publishing and consumer / producer use the same default configuration we are able to match the id of the schema at registration and at deserialization / serialization time. More on naming strategies can be found in the Apicurio Registry guide.
As we have seen, the minimalistic configuration applied allows our application to enable Avro, Protobuf and JSON-Schema registration and enforcement. However we may want to be more explicit in our naming strategy to avoid schema collision, to ensure consumer and producer use the same schema and to avoid schemas being accidentally moved. This is where you will need to roll up your sleeves and dig into how your framework works with your chosen schema registry - in this example how Quarkus uses the SmallRye Reactive Messaging that leverages the Apicurio Java Kafka Serializer and Deserializers. Again, this is extra configuration, but again you should be assert that this works as expected.
The example above works well in a problem space where the domain is limited and there is a close relationship between consumers and producers - often in a point-to-point integration and where there are often multiple distributed schema registries.
In some situations schemas may stretch over a wider domain or be centralised and managed by third parties or by teams not associated with the consumers or producers. This is often the case for event sourcing patterns. In these cases a contract-first approach may be more appropriate.
In practical terms for our example a contract-first means that the schema should be available in the schema registry prior to the consumers and producers being started and without auto publishing.
Let’s start a new standalone Apicurio Registry:
> docker run -d -p 8082:8080 quay.io/apicurio/apicurio-registry-mem:2.4.2.Final
…will start a new Apicurio registry available on port 8082. The UI can then be used to load the schema:
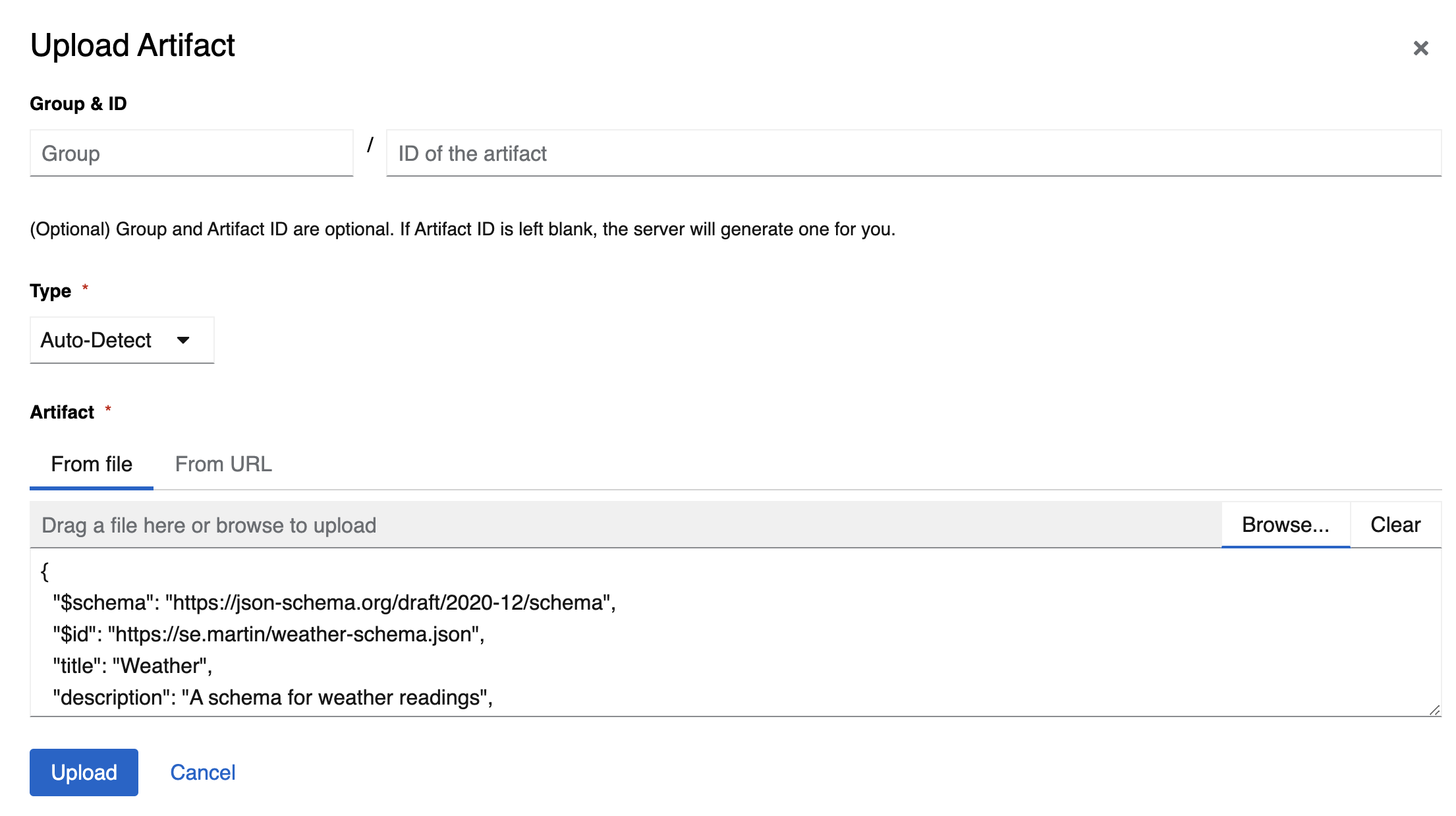
Apicurio regards each schema as an artifact and will helpfully generate an identity for that artifact if none is given, in my case a UUID 691f3e21-1fb8-41c8-bcb5-2193b3897c27. Note that Apicurio will allow you to upload the same schema again, creating two artifacts with different identities, as seen below:
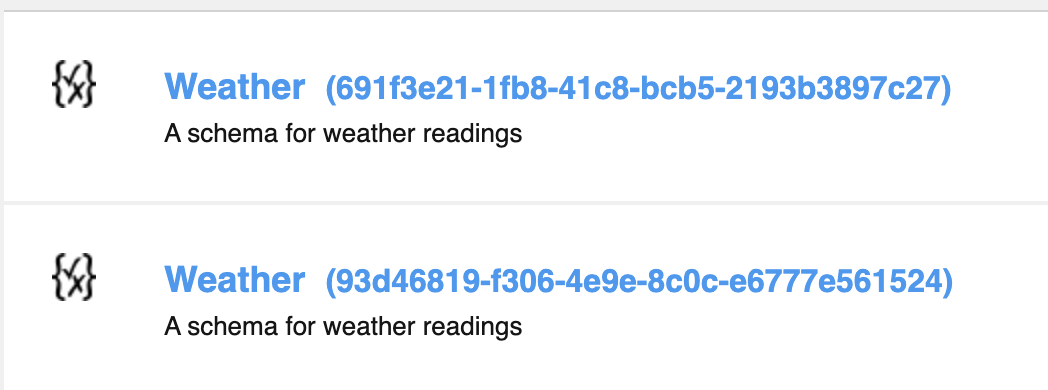
Again it is well worth investigating how you will organise your schemas, and what features your particular Schema Registry can offer to help with this. For example we could use the Group feature to group the weather schemas and other teams have their own Groups. It is strongly recommended that you investigate permissions to ensure users can only update, delete or version schemas belonging to them (whereas read permissions can be a little more loose).
The example above uses the Apicurio UI to manually register a schema but this could also be done using a REST API or with a Maven plugin.
If you are looking at a contract first solution it is a good idea to consider using git (or similar) to version control a single master copy of the schema. Git is especially useful when designing or versioning a schema as you can use familiar collaborative tools before producing a final acceptable version.
It is also a good idea to consider moving the schema out of the application repository. Keeping multiple copies of the schema can lead to manually introduced “cut-and-paste” errors that may result in a failure at runtime.
Pipelines for schema delivery can also be a good idea. For example, when versioning an existing schema you may want to do a compatibility test, and if that fails then the pipeline fails - this gives the schema owner immediate feedback rather than waiting for an application to fail at runtime, when the schema is auto published. In addition these pipelines can be used to generate client applications, for example the Avro Java classes used here that can then be released as libraries. Beware timing issues thoug - don’t make your Java client available before the schema is published.
Now that we have registered a schema we will need to tell our producers and consumers which schemas to use. Fortunately in Quarkus this is just by changing the configuration:
%prod.mp.messaging.outgoing.out-weather-json.apicurio.registry.auto-register=false
%prod.mp.messaging.outgoing.out-weather-json.apicurio.registry.artifact.group-id=weather
%prod.mp.messaging.outgoing.out-weather-json.apicurio.registry.artifact.artifact-id=weather-json-schema
This will, in prod mode, turn off auto registration of the JSON schema and instruct the producer to use a schema registered in group weather with an id weather-json-schema. If the schema doesn’t exist then the Quarkus app will give a hint:
2024-09-18 11:43:38,959 ERROR [io.sma.rea.mes.kafka] (smallrye-kafka-producer-thread-0) SRMSG18260:
Unable to recover from the serialization failure (topic: weather-json)... :
io.apicurio.registry.rest.client.exception.ArtifactNotFoundException: No artifact with ID 'weather-json-schema' in group 'weather' was found.
The above error is just one of hundreds that quickly build up when running the example app before the schema is published. As I have mentioned in previous blogs it is good to plan for what happens when something goes wrong. In this case data being sent to the producer is lost forever. It is good to have in the back of your mind that the Schema Registry is now a critical part of your infrastructure, and needs to have an SLA that matches the requirements of your Kafka clients.
In part one we took a look at popular Schema frameworks. In part two we have taken a look at the role of the Schema Repository and hopefully illustrated the power of the solution in ensuring data can be written and consumed independently and with confidence.
The example application has a very heavy bias towards Java, Quarkus and Apicurio. This is intentional to illustrate the need to deep dive into your chosen Schema Registry and how you interact with it. Verify that things are working as you expect, this is the key to ease of mind.
We have looked at both code-first and contract-first approaches to schema management. We have looked at how the Schema Registry can be used to catalogue schemas and looked at possible paths for automation.
One thing we have not mentioned, but that is worth considering, is the context of a schema in a Schema Registry. Most Schema Registry products focus on the interaction with the Kafka clients, few, if any, consider how we could do “schema discovery” - i.e. provide a service that allows a user to work out for themselves which schema is relevant for their need and how to apply it. This context is not documented in any of the schema offerings either (for comparison consider the OpenAPI Contact Object which gives you a hint of where to start).
We have not looked at how to version schemas and how your Schema Registry could support that, another topic that is of great importance, and will be dealt with in a later blog post.
Hopefully this has been a useful introduction. Best of luck with your schemas!
Bonus: Part 3 is available and looks at schema evolution.