Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

An update on the journey of optimizing a text-similarity HTTP request handler with the new swissmap map implementation introduced in Go 1.24.
In the first and second parts, I told the little tale on how I optimized a Go implementation from an article on Medium, basically increasing the average throughput by 3x.
In this part, I’ll re-run the benchmarks using the exact same codebase as at the end of part 2, but compiled with Go 1.24.1.
Go 1.24, released in february 2025, introduced a completely rewritten implementation of the ubiquitous built-in map type, based on the concept of swiss tables. I won’t go into details on how the legacy map implementation differs from the new swiss table implementation, the two preceding links does a good job explaining hashtable internals and how the implementations differ.
In the two previous parts, we identified that the map type was used widely throughout the original implementation. In part, we replaced map usage for sets with a custom set type, but we also got a nice speedup by creating remaining map instances with sensible initial sizes set.
Due to the heavy use of map, I thought it would be interesting to see what kind of performance benefits (or regressions?) the new map implementation in Go 1.24 would bring.
I simply updated Go to 1.24.1, rebuilt the Go binary using go build main.go and then used the same https://k6.io/ as before.
As reference, the closing figures in the last part were:
checks.........................: 100.00% 2064722 out of 2064722
✓ http_req_duration..............: avg=43.5ms min=429µs med=18.82ms max=1.04s p(90)=119.91ms p(95)=175.68ms
iterations.....................: 1032361 6882.294302/s
I re-ran the benchmark three times, which averaged into the following result:
checks.........................: 100.00% 2232386 out of 2232386
✓ http_req_duration..............: avg=27.32ms min=359µs med=14.47ms max=1.24s p(90)=59.91ms p(95)=95.01ms
iterations.....................: 1116193 7441.339203/s
Cool! Moving to Go 1.24 resulted in a gain of approx. 550-600 additional req/s, or ~8%. What’s perhaps even more interesting is that the average latency was almost halved, with the p(90) and p(95) durations seeing large decreases. It definitely seems that something in Go 1.24 significantly decreased the outliers, providing more consistent performance.
Are these gains fully connected to the swiss table map implementation being more efficient, or are there other significant improvements in Go 1.24, for example to the garbage collector or other runtime internals? Perhaps running with profiling can reveal something?
As before, the text-similarity program is compiled with import _ "net/http/pprof" to enable profiling. Let’s start by looking an memory allocations.
go tool pprof -alloc_objects and go tool pprof -alloc_space are used after 30 seconds to collect memory profiles.
In the table below, I’ve included the figures from part 2 of the blog series, and added an entry for Go 1.24.1.
| Scenario | Requests performed | Num allocations | Memory allocated | Allocations per request |
|---|---|---|---|---|
| No initial map capacity | 152 227 | 17 722 736 | 75.83 GB | 116.4 |
| With initial map capacity | 181 626 | 4 398 554 | 77.68 GB | 24.22 |
| Go 1.24.1 | 239 807 | 7 954 979 | 78.02 GB | 33.17 |
Interestingly, the total number of memory allocations has almost doubled, while the total amount of memory allocated is basically the same. Since the throughput is significantly higher, allocations per request has increased from 24.2 to 33.2. However, it does seem as the overhead of memory allocations is quite a bit smaller with Go 1.24 given that the throughput is up and latencies are down.
Unsurprisingly the graph view of total memory allocated shows that the frequency map code (which uses map) and the 3rd party strset are the largest memory allocators.
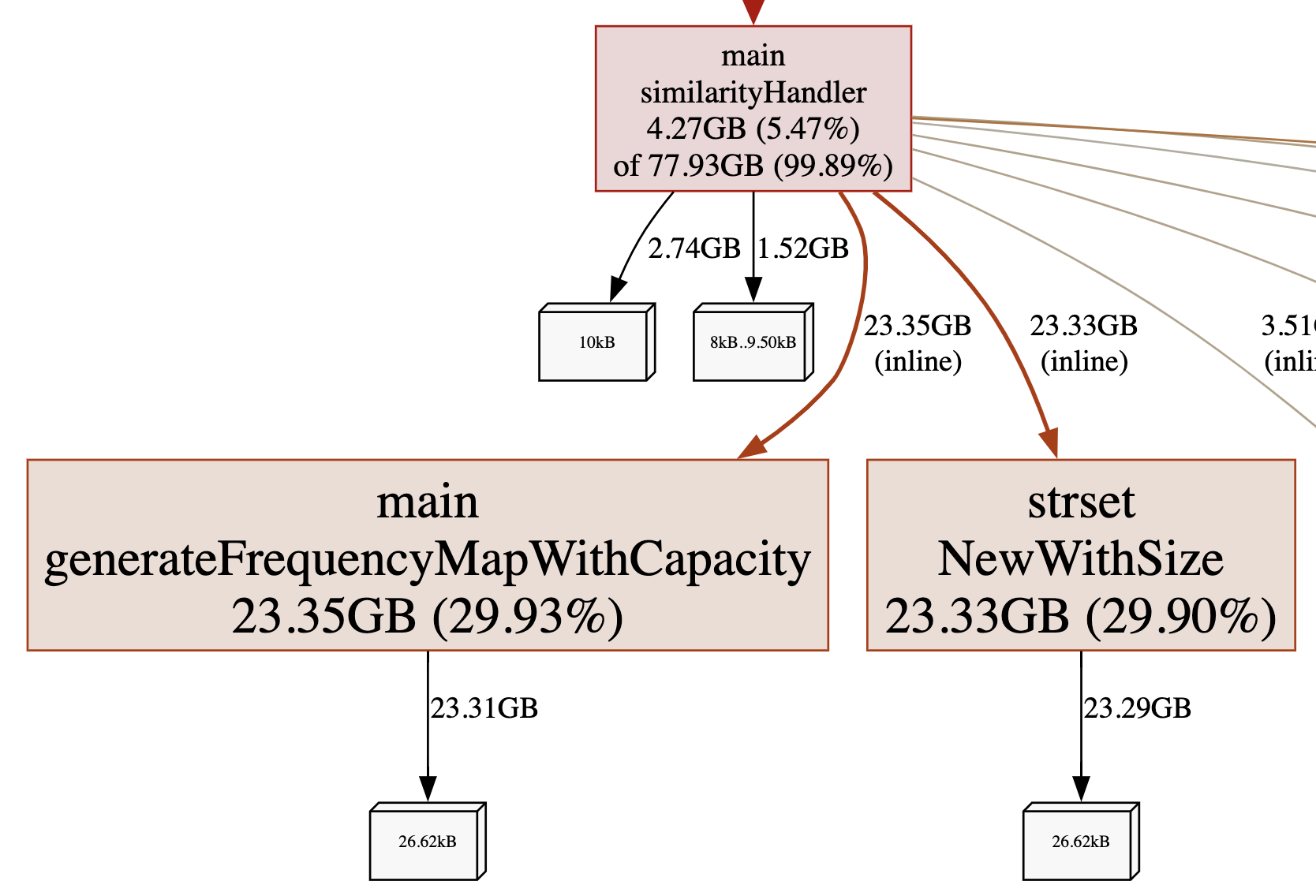
A 30-second CPU profile captured and displayed as a full graph doesn’t tell us very much at a glance:
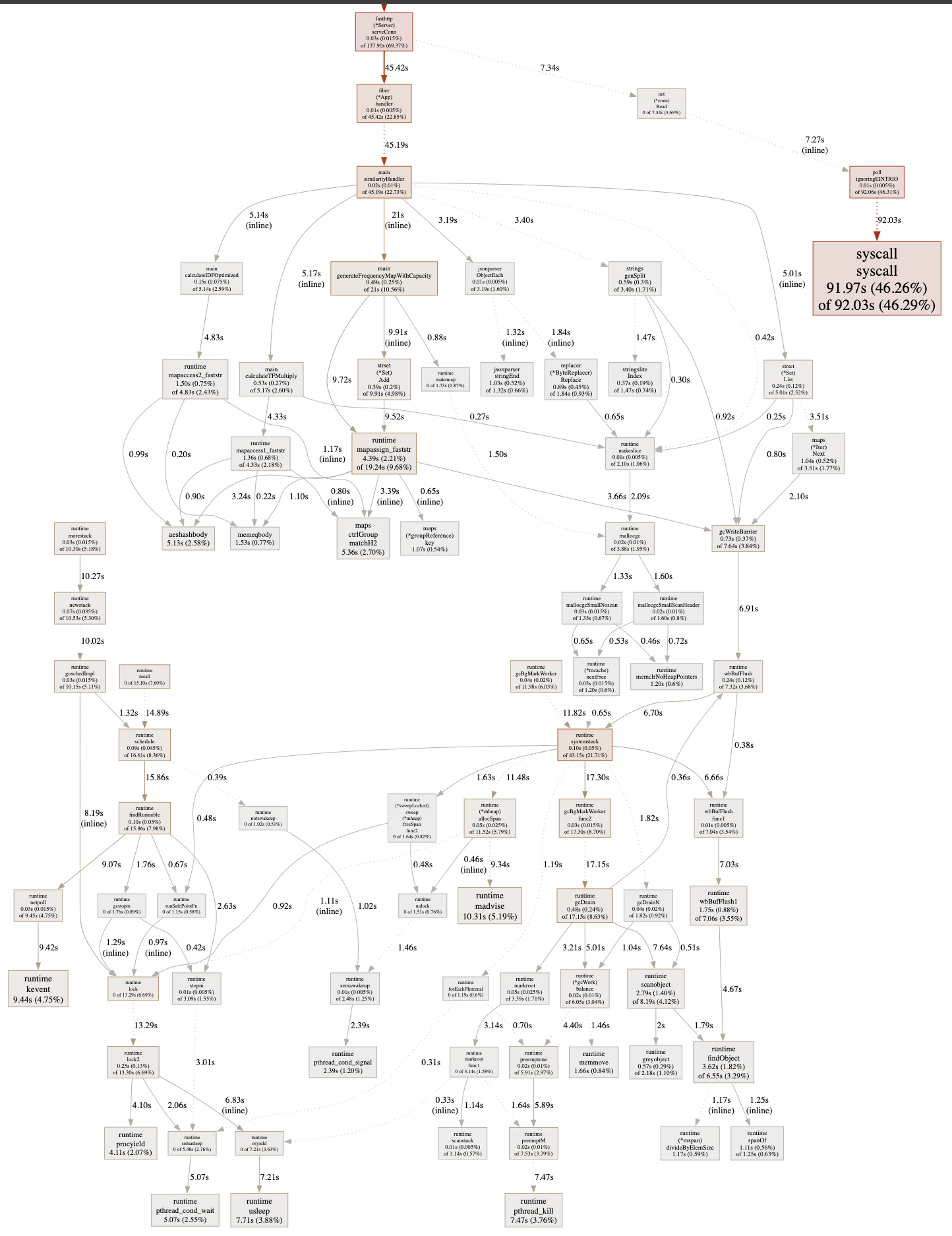
What it however does tell us is that there are no standout CPU consumers (expect syscall), most boxes are of similar sizes. syscall in the upper-right corner is related to how the OS reads/writes data for network traffic. Nothing we can do anything about.
In order to get more insights, we need to compare the new CPU profile with an old one. I haven’t saved any old profiles, but luckily we can easily switch back to Go 1.23.4 using GOTOOLCHAIN=go1.23.4 go build main.go together with specifying go 1.23.4 in go.mod. After capturing a fresh 30 second CPU profile using go tool pprof, we can compare map usage more closely.
In this side-by side view with Go 1.23 to the left and Go 1.24 to the right, we see some of the internal changes such as the new group and control words in use.

What we do see is that in Go 1.24, about half the amount of time is spent inside the mapaccess1_faststr, mapaccess2_faststr and mapassign_faststr functions, though the totals adds up somewhat similarly. Still - the performance is clearly better with the Go 1.24.1 swiss table map implementation - remember that the CPU profile only shows us how much time was being spent in a given function/method, not the actual amount of work that was performed during the time spent.
Since part 2 was released, Fiber and several other 3rd party dependencies has been updated. I updated all versions using go get -u ./.... rebuilt and ran three test runs.
No noticeable difference could be seen, performance in req/s averaged to about 7400 req/s over three runs.
Back in 2021, a proposal for compiling Go code against more fine-granular and explicit CPU capabilities was accepted and implemented. In short, on x86 CPUs, one can use the GOAMD64 environment variable to tell the Go compiler which level of CPU capabilities to compile against. The possible values are v1, v2, v3 and v4 - which closely maps to x86 microarchitecture levels. Typically, CPUs supporting SIMD through SSE, AVX, AVX2 and AVX512 can utilize special CPU instructions to perform certain tasks more efficiently - if the underlying compiler (be in Go or some other compiler) knows how to produce assembly that uses those instructions.
In most cases, GOAMD64=v3 is a sensible choice supporting Intel and AMD CPUs with AVX2 (256-bit SIMD registers) including Intel Haswell and AMD Ryzen and later. If not specified, the Go compiler will default to v1 which basically includes all mainstream x86 CPUs released since 2003 or so.
I did experiment with GOAMD64 when writing part 1 of this series, but at that time, I couldn’t really discern any performance differences. However, since the new map implementation includes use of SIMD instructions, I recompiled the Go 1.24.1 version with GOAMD64=v3 go build main.go and re-ran the benchmark three times.
The best result:
checks.........................: 100.00% 2285668 out of 2285668
✓ http_req_duration..............: avg=25.71ms min=358µs med=14.2ms max=1.1s p(90)=56.3ms p(95)=87.69ms
iterations.....................: 1142834 7618.650654/s
I.e. another 2-3% performance increase (~180 req/s), sustaining an average of 7619 req/s. Not bad. The average was about 7530 req/s. so in this case, it seems as GOAMD6=v3 does improve overall performance somewhat.
Note: I should mention that benchmarking on an Intel MacBook Pro does produce somewhat inconsistent results, probably due to thermal throttling. I typically close all unrelated programs while benchmarking and let the computer cool down (e.g. the fan shouldn’t be heard) between runs.
In part1 and part2, we took the code from the original Medium article, benchmarked it on my MacBook and then improved upon the Go solution.
In this part, we upgraded to Go 1.24 and its new swiss table-based map implementation, netting about 7-8% increase in throughput and almost halving the average and p(90)/p(95) latencies. Furthermore, use of GOAMD64=v3 to allow use of advanced SIMD CPU instructions seems to have netted another 1-2% increase. We also saw that the number of memory allocation went up with Go 1.24, but with an increased throughput, it does seem as these allocations are more efficient with 1.24.
The final benchmark results:
Original implementation from Medium article : 2266 req/s, avg: 168 ms.
After part 2 : 6882 req/s, avg: 43.5 ms.
After part 3, with Go 1.24 and GOAMD64=v3 : 7530 req/s, avg: 26.2 ms.
In a future installation, I may take a look at implementing the text-similarity program using worker pools in order to minimize memory allocations.
Thanks for reading! // Erik Lupander