Blogg
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn
Här finns tekniska artiklar, presentationer och nyheter om arkitektur och systemutveckling. Håll dig uppdaterad, följ oss på LinkedIn

Go has been around for over 16 years, with more than a decade of stable production use since version 1.0 that was released in 2012. The latest release - 1.26 - came out in February this year.
Every new release has brought new updates, often with a focus on the toolchain and runtime. When it comes to adding new features to the language itself or to the standard library, the development pace has been deliberately slow and conservative.
The introduction of generics that was part of release 1.18 (in 2022) was highly unusual in that respect and gained a lot of attention. In this blog post, we will look at some of the updates that have been made to the language and standard library in the subsequent releases that did not draw as much attention but still delivered useful and in some cases long-awaited features.
According to JetBrains Data Playground, more than 2 million developers use Go as their primary programming language today and Go is ranked as number 4 on their language promise index.
One of the major contributing factors to its popularity is that the design philosophy behind Go from the start has focused on developer efficiency. The language is designed with simplicity and maintainability in mind. It has a clear and simple syntax, few abstractions and an explicit control flow. Other reasons for its popularity are the built-in concurrency features, out-of-the-box tooling and fast compilation times.

When the 1.0 version was released in March 2012, it came with a compatibility promise, stating that:
It is intended that programs written to the Go 1 specification will continue to compile and run correctly, unchanged, over the lifetime of that specification. At some indefinite point, a Go 2 specification may arise, but until that time, Go programs that work today should continue to work even as future “point” releases of Go 1 arise (Go 1.1, Go 1.2, etc.).
Since then, the Go team has focused on keeping this promise, introducing new features slowly, prioritizing long-term stability and maintainability over nice-to-have features.
The biggest change to the language so far, was the introduction of generics that came with the 1.18 release. This was a major update that had been under discussion for a very long time, more or less since the first release of Go. The Go team managed to implement the new generics features into the language without breaking the compatibility promise.
A year later, the Go team posted a clarifying statement saying that a breaking Go 2 specification will never happen. Compatibility will remain a top priority and all updates to the language will continue to be performed in a careful, compatible way.
Go is released with two feature releases per year. Many of these releases primarily focus on updates to the implementation of the runtime and toolchain, with some minor additions to the standard library. And so they do not gain the same attention as the historical 1.18 release did. Still, looking back at the releases that have been made after the 1.18 release, there have been some valuable additions made to the language and to the standard library and I will cover some of them here.
Note that this blog focuses on updates to the language and standard library. As already mentioned a lot of updates have taken place related to the implementation and toolchain, but that is not the objective for this blog post. The list below is also not covering every single addition that has been made to the language and standard library. To get the full details, please read the official Release History section. The list below is mainly arranged in chronological order, not in order of importance.
The sync/atomic package is useful when you want safe concurrent access without using mutexes, ensuring atomic reads and writes across goroutines. With release 1.19, atomic types were added to the package which simplified its usage. Prior to this release, regular types were used like this:
var counter int64
atomic.AddInt64(&counter, 1) // atomic increment
c := atomic.LoadInt64(&counter) // atomic read
From version 1.19 it is now possible to do like this:
var counter atomic.Int64
counter.Add(1) // atomic increment
c := counter.Load() // atomic read
Using the new atomic types ensures that non-atomic access to the variables is not possible. It also ensures type safety and removes the need to use pointers. A small but nice improvement.

Since release 1.20 it is possible to combine multiple errors into a single value. The purpose is to make it easier to handle situations where multiple errors can occur, and you want to return them together rather than just the first one.
Errors are joined like:
errors.Join(errFirst, errSecond)
and can be inspected using the errors.Is() and errors.As() functions as for any other error.
In Go, the context (context.Context) is used to carry request-scoped variables, and for propagating cancellation / timeouts.
The developer has been given a more fine-grained control of the Context with the following additions:
With release 1.20 came the new function WithCancelCause, providing a way to cancel a context with a given error.
With release 1.21 four new context functions were added, WithoutCancel for ignoring parent cancellation,
WithDeadlineCause and WithTimeoutCause for adding cancellation reason as well as AfterFunc
for registering a callback that runs automatically when a context is canceled.
Structured (key-value based) logging was brought into the standard library as part of release 1.21, as the new log/slog package, which was long awaited by the Go community that up until then had used some different third party libraries such as Zap and Logrus. The package comes with built-in JSON support, context integration and good performance and is now the de-facto standard for structured logging with Go.
A logger could be instantiated like:
handler := slog.NewJSONHandler(os.Stdout, &slog.HandlerOptions{
Level: slog.LevelDebug, // minimum log level
})
logger := slog.New(handler)
And used like:
logger.InfoContext(ctx, "User logged in",
slog.String("user_name", userName),
slog.Int("login_attempts", attempts),
slog.String("ip_address", ipAddress),
slog.Bool("is_admin", isAdmin))

Thanks to the introduction of generics, it became possible to write type-safe, reusable slice and map utilities. The slices and maps packages were introduced in release 1.21 and more functions have been added in later releases.
These are very handy functions that developers previously had to write as helper functions for every type.
Slices holds functions such as Sort, Clone, BinarySearch, Index, Replace, Values, Delete.
Maps holds functions such as Keys, Values, Insert, Collect, Clone, DeleteFunc.
Example with slices:
package main
import (
"fmt"
"slices"
)
func main() {
nums := []int{4, 2, 3, 2, 5, 1}
// Clone the slice
numsCopy := slices.Clone(nums)
// Sort the clone
slices.Sort(numsCopy)
// Remove duplicates from the clone
numsCopy = slices.Compact(numsCopy)
fmt.Println(nums) // [4 2 3 2 5 1]
fmt.Println(numsCopy) // [1 2 3 4 5]
}
Three new built-in functions were added as part of release 1.21:
Example:
package main
import (
"fmt"
)
func main() {
fmt.Println("min:", min(3, 5, 1)) // min: 1
fmt.Println("max:", max("A", "B", "C")) // max: C
numbers := []int{1, 2, 3}
clear(numbers)
fmt.Println("after clear:", numbers) // after clear: [0 0 0]
}
This was a change to for loop scoping that had previously often led to some developer confusion. Before Go 1.22, all iterations of a for loop shared the same loop variable rather than each iteration getting its own copy. This caused a classic bug when using goroutines or closures inside a loop:
package main
import "fmt"
func main() {
funcs := []func(){}
for i := 0; i < 3; i++ {
funcs = append(funcs, func() {
fmt.Println(i)
})
}
for _, f := range funcs {
f()
}
}
Running this code snippet using a Go version prior to 1.22 would result in the following output:
3
3
3
The reason for this being that all the closures captured the same shared i variable; by the time the second loop calls them, i has the value of 3. This might seem surprising and not how one would expect it to work. Therefore, this behaviour was changed in version 1.22, so that each iteration of the loop now creates new variables. And so the results for the above example becomes:
0
1
2
Since release 1.22, for loops can now range over integers:
for i := range 3 {
fmt.Println(i)
}
Before Go 1.23 there was no standardized way available for defining iterable types.
With the 1.23 release came a new iter package, to standardize user-defined iteration
and to integrate it with for range.
The package defines two main iterator types:
type Seq[V any] func(yield func(V) bool)
type Seq2[K, V any] func(yield func(K, V) bool)
A sequence (Seq) is a function that produces values by invoking a callback function, conventionally named yield. Iteration stops when the sequence ends or yield returns false.
Since this release, for loops allow ranging over iterator functions. And packages such as slices and maps have added iterator support.
For example it is possible to iterate over a slice using the iterator function Values:
nums := []int{10, 20, 30}
for v := range slices.Values(nums) {
fmt.Println(v)
}
The math/rand/v2 package that was introduced as part of release 1.22, is the first v2 package added to the standard library.
The Go team noticed some issues with the original math/rand package that they wanted to fix, where some of the desired changes were not possible to do without introducing breaking changes. Due to the compatibility promise, this meant a v2 version was needed. The math/rand/v2 API fixes several design issues in the v1 API, including eliminating global shared state and allowing the use of modern, high-quality random number generators as well as providing a cleaner API.
Using this new API, generators are fully independent but by using the same seeds, the generated sequences will be identical, which is useful for example in test scenarios.
For example:
package main
import (
"fmt"
"math/rand/v2"
)
func main() {
r1 := rand.New(rand.NewPCG(1, 42))
r2 := rand.New(rand.NewPCG(1, 42))
// Both generators produce the same sequence
for i := 0; i < 5; i++ {
fmt.Println("r1:", r1.IntN(100), "r2:", r2.IntN(100))
}
}
would always lead to the same output:
r1: 5 r2: 5
r1: 51 r2: 51
r1: 8 r2: 8
r1: 41 r2: 41
r1: 30 r2: 30
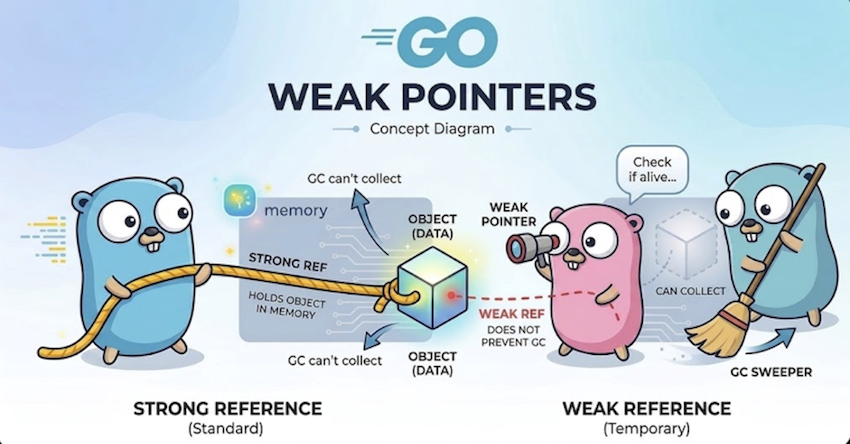
The new weak package (introduced in release 1.24) makes it possible to keep references to values without preventing them from being garbage collected. If the memory they’re pointing to gets cleaned up, the weak pointer automatically becomes nil. And one can convert a weak pointer into a strong one as needed.
This could be valuable for example for caching implementations. A weak reference makes it possible to check if a value still exists. If it doesn’t, nil will be returned:
package main
import (
"fmt"
"runtime"
"weak"
)
type Person struct {
Name string
}
func main() {
// Create a strong reference
p := &Person{Name: "Sarah Johnson"}
// Create a weak pointer
wp := weak.Make(p)
fmt.Printf("value: %+v\n", wp.Value())
// Drop the strong reference
p = nil
// Ask GC to run
runtime.GC()
// Try to access again
fmt.Printf("value: %+v\n", wp.Value())
}
The above code would result in:
value: &{Name:Sarah Johnson}
value: <nil>
In release 1.25, there was a new method added for WaitGroups that simplifies its usage. Prior to this release, using WaitGroups would typically follow a pattern like:
nums := []int{1, 2, 3, 4, 5}
var wg sync.WaitGroup
for _, n := range nums {
wg.Add(1) // manually increment counter
go func() {
defer wg.Done() // manually decrement counter
fmt.Printf("Processing %d squared = %d\n", n, n*n)
}()
}
wg.Wait() // wait for all goroutines to finish
But with the addition of the new Go() method, which performs the above calls to
wg.Add(1) and wg.Done() behind the scenes, we now only need to do the following:
nums := []int{1, 2, 3, 4, 5}
var wg sync.WaitGroup
for _, n := range nums {
wg.Go(func() {
fmt.Printf("Processing %d squared = %d\n", n, n*n)
})
}
wg.Wait() // wait for all goroutines to finish
A small addition, but it leads to cleaner and less error-prone code, especially for more complex scenarios.
The new testing/synctest package that came with release 1.25 provides support for testing concurrent or time-dependent code in a deterministic and reliable way, without having to wait in real time. It provides a so-called “bubble”, an isolated environment with a virtual clock, where time advances only when all goroutines in the bubble are “durably blocked”. A goroutine is considered durably blocked if it is blocked and can only be unblocked by another goroutine in the same bubble.
The package provides the following two functions:
func Test(t *testing.T, f func(*testing.T)), which executes f in a new bubble, waits for all goroutines in the bubble to exit before returning. It will fail if the goroutines become deadlocked.func Wait(), which blocks until every goroutine within the current bubble (other than the current one) is durably blocked.Example:
package main
import (
"context"
"testing"
"testing/synctest"
"github.com/stretchr/testify/assert"
)
func TestAfterFunc(t *testing.T) {
synctest.Test(t, func(t *testing.T) {
ctx, cancel := context.WithCancel(context.Background())
afterFuncCalled := false
context.AfterFunc(ctx, func() {
afterFuncCalled = true
})
cancel()
synctest.Wait()
assert.True(t, afterFuncCalled)
})
}
By calling synctest.Wait() above, we can be sure that the goroutine spawned by AfterFunc has finished when reaching the assert statement. Without the synctest package we would have needed to instead add some estimated waiting time before doing the assert, which would make the test become either unnecessarily slow or flaky, since the time for that goroutine to finish could vary between runs.
For someone new to Go, coming from a different programming language, the lack of certain features might seem a bit surprising. One such thing has been that there was no simple way to create a pointer to a value of a built-in type.
For example, before one would have to do the following to create a pointer to a string:
str := "hello"
p := &str
But in release 1.26 this has finally been solved so that the built-in new function can be used on
expressions and not just types.
So now the following is enough:
p := new("hello")
A small update of the language, but a very welcome one, getting rid of the need to write pointer helper functions which was quite common in Go projects before this addition, for example when dealing with structs with optional fields.
Release 1.26 also introduced errors.AsType, a type safe alternative to errors.As.
Using errors.As one had to do something like:
var e SomeError
if errors.As(err, &e) {
...
}
But now the following is enough:
if e, ok := errors.AsType[SomeError](err); ok {
...
}
Meaning you can specify the error type as part of the function call, keeping the code shorter and the error variable scoped to the if block.
Several new crypto packages have been added such as crypto/ecdh providing support for Elliptic Curve Diffie-Hellman key exchanges
(release 1.20) and crypto/mlkem for post-quantum key exchange (release 1.24).
A new cmp package was added in release 1.21 for comparing ordered values.
A new unique package was added in release 1.23.
It lets you deduplicate values so that they point to a single, canonical, unique copy.
The latest Go release, 1.26, includes two experimental packages. The intention of an experimental package is to make a feature available for real-world testing and feedback before committing to a stable API. Experimental features are therefore not covered by Go’s compatibility promise. They might need an opt-in flag and are not recommended for production. For example, slog was first an experimental package, before becoming a stable API.
Go 1.26 contains the experimental simd/archsimd package, providing access to architecture-specific SIMD operations, which my colleague Erik has written a blog series about.
It also includes an experimental runtime/secret package intended to ensure that sensitive data, such as cryptographic key material, doesn’t linger in memory longer than necessary.
All in all, there have certainly been some nice features added to the Go language and the standard library during recent releases. Some of which now seem so natural for every-day use that it is easy to wonder how did we ever manage without them.
Release 1.27 is expected around August, and a new package generating and parsing UUIDs might be included in this release. Looking forward to that and other additions and improvements!
One final note: I had some fun generating the illustrations for this blog using Gemini. Getting every detail right with AI is tricky, so please note that the images may not be 100% accurate.